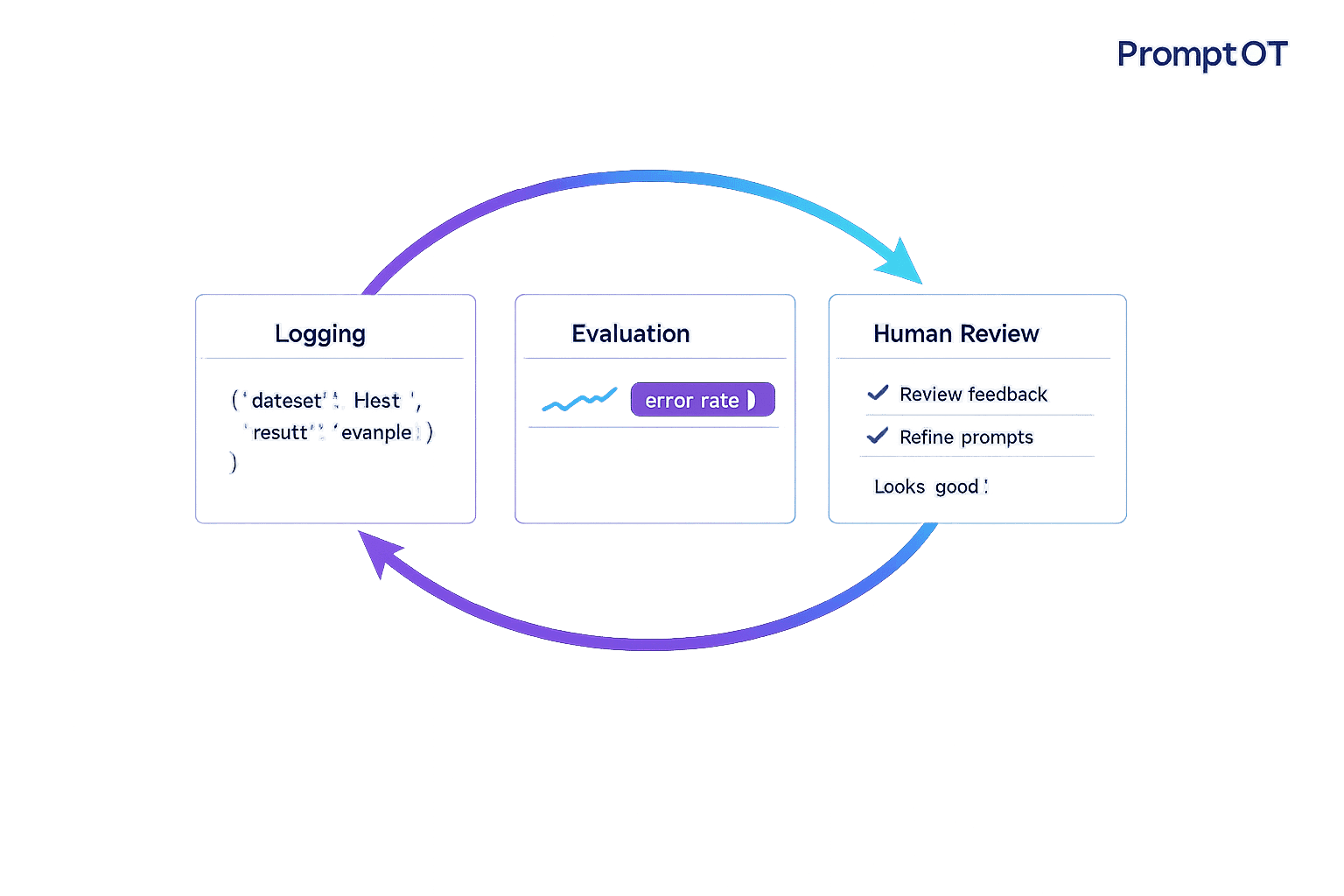
Feedback loops are the secret to creating better AI prompts. Instead of relying on trial and error, feedback loops let you refine prompts by analyzing outputs, identifying issues, and making improvements. They ensure your AI delivers consistent, accurate, and user-friendly results.
Here’s how feedback loops work:
- Capture Data: Log prompt versions, inputs, outputs, and metadata.
- Evaluate Outputs: Use user ratings, automated scoring, or human reviews.
- Analyze Issues: Identify recurring problems like errors, tone mismatches, or hallucinations.
- Refine Prompts: Adjust instructions, add examples, or rephrase.
- Re-Test: Validate improvements before deployment.
Key Benefits:
- Improved Results: Teams using weekly feedback cycles see quality improve 2.1x faster.
- Cost Savings: Risk-tiered systems reduce human review costs by 40–55%.
- Fewer Errors: Structured refinement cuts down flagged issues and silent regressions.
Feedback loops combine human insight with automation to ensure your prompts stay effective, even as models evolve. Done right, they transform prompt engineering into a reliable, repeatable process.
Build a Prompt Learning Loop - SallyAnn DeLucia & Fuad Ali, Arize
sbb-itb-b6d32c9
How Feedback Loops Work in Prompt Engineering
Feedback loops turn prompt engineering into a structured, repeatable process rather than a trial-and-error exercise. By systematically identifying issues, refining instructions, and verifying improvements, teams can ensure consistent, high-quality outputs while addressing potential problems before they affect users.
Iterative Refinement and Error Correction
The refinement process typically involves four stages: creating the initial prompt, evaluating its response, refining the instructions, and reassessing the output. This cycle helps teams catch subtle failures, known as silent regressions, which may not show up during basic checks but can cause significant issues in practical use.
In February 2026, Parker Gawne, founder of the AI automation agency Syntora, introduced a 60-second rating system for all AI sessions. Team members rated outputs on a scale from 1 (unusable) to 5 (ready to use) and documented key observations. After three months of tracking, Syntora developed a refined "v3" prompt template that included clearly defined "Reference" and "Boundaries" sections. This structured feedback loop made their prompts three times more effective, cutting down on token waste and reducing manual rework.
Another key to effective refinement is layering constraints to explicitly block undesired behaviors. This method, called "Anti-Pattern Fencing", addresses failure modes that only appear in practical applications. Studies show this approach can lead to up to 2.1× faster improvements in quality.
While automation plays an important role, human input remains critical for refining prompts with greater precision.
Team Member Collaboration
Automated systems are excellent at catching technical errors, like JSON validation failures. However, human reviewers bring essential context and judgment, identifying nuanced issues such as inconsistencies in tone, logic, or adherence to policy. In regulated industries, experts in fields like law, medicine, or finance are invaluable for ensuring prompts meet the required standards.
Collaboration is further strengthened by tiered routing systems. In this setup, low-risk outputs are automatically approved, while medium- and high-risk items are escalated to human reviewers based on predefined service-level agreements (SLAs). A 2024 Deloitte report observed:
"Risk-tiered HITL with clear SLAs is the fastest path to reliable AI in regulated environments".
This approach not only improves reliability but also cuts human review costs by 40–55%. Regular calibration sessions, often lasting 30 minutes, allow teams to align on edge cases and refine evaluation rubrics, minimizing inconsistencies. Shared dashboards also provide visibility, enabling product managers and engineers to link user behavior with specific prompt versions.
While human collaboration is essential, automation can further streamline feedback loops.
Automation in Feedback Loops
Automation simplifies repetitive tasks and accelerates the feedback process. Advanced models like GPT-4 or Claude 3 can act as evaluators, scoring outputs based on clarity, logic, and adherence to constraints. Automated systems then classify responses into risk tiers: low-risk outputs are auto-approved, while high-risk or uncertain ones are flagged for human review.
In 2024, xAI incorporated automated feedback loops into its Grok 3 model for UI prototyping. The system allowed the model to reference previous UI designs and integrate user feedback (e.g., "adjust the color palette to blues and greens") without losing earlier progress. This approach reduced development times by 20% and improved user satisfaction by 15%.
Platforms like PromptOT make this process even smoother. By combining version control with built-in safeguards, teams can create prompts using modular blocks (e.g., role, context, instructions, guardrails). Features like A/B testing and instant rollbacks ensure that underperforming versions can be quickly replaced. Webhook alerts notify teams of validation failures, enabling rapid iterations without requiring constant manual oversight. Storing prompt templates as versioned files also makes it easy to track which changes led to improvements and which caused regressions.
Research Studies on Feedback Loop Impact
Recent studies highlight the powerful role feedback loops play in improving prompt quality. From coding tasks to mathematical reasoning, these iterative processes have proven to boost performance significantly across various domains.
LLMLOOP Framework Study
In September 2025, researchers from the University of Auckland and King's College London introduced the LLMLOOP framework at ICSME 2025. This tool focused on refining Java code prompts through five iterative loops, addressing issues like compilation errors, static analysis flaws, test failures, and mutation problems. When tested on the HUMANEVAL-X benchmark, the framework achieved a 14% improvement in pass@10 rates, meaning it generated correct code more consistently compared to single-pass methods. Similar iterative approaches have shown comparable benefits in other areas as well.
Code Translation Feedback Loops Study
A December 2025 study explored the impact of feedback loops on translating C code to Rust. The results were striking - success rates increased by as much as 50%. Interestingly, the study revealed that when feedback loops were in place, the choice of the underlying language model became less important. In fact, smaller models equipped with feedback loops often outperformed larger models without them. Using a "generate-and-check" approach, researchers refined Rust code by combining generation, compiler verification, and test validation. Error messages from failed attempts were used to guide subsequent iterations, resulting in more reliable code translations.
Latitude Case Study on LLM Outputs
The benefits of feedback loops extend beyond coding tasks. In January 2025, Latitude implemented a feedback loop system for an AI banking assistant. Engineers collaborated with banking experts to refine responses, ensuring they met industry standards for accuracy and relevance. While automated systems handled many errors, domain experts identified subtle failures - responses that were technically correct but violated banking norms. Latitude's CEO, César Miguelañez, emphasized the importance of constant evaluation:
"Regular evaluation and adjustment of feedback loops are necessary to prevent negative side effects and ensure continuous improvement".
Other domains have seen similar success. For instance, a November 2025 study by Deepak Pandita and Tharindu Cyril Weerasooriya introduced ProRefine, a method that dynamically optimized prompts during inference using a three-agent system: Task LLM, Feedback LLM, and Optimizer LLM. When tested on datasets like GSM8K, ProRefine improved accuracy by 3 to 37 percentage points over zero-shot baselines. In word sorting tasks, the Llama 3.1-8B model achieved a 37-point accuracy increase, rivaling the performance of models eight times its size. These findings highlight the essential role of iterative feedback - both human and automated - in refining prompts and maintaining quality.
Measured Benefits and Implementation Best Practices

Measured Benefits of Feedback Loops in Prompt Engineering
Measured Gains from Feedback Loops
Feedback loops can drive impressive performance improvements, and the results are easy to quantify. For instance, Syntora implemented a three-month feedback loop system that made their prompts 3x more effective while significantly reducing manual rework.
These benefits aren’t limited to just one aspect. Structured prompt learning with feedback loops can deliver state-of-the-art results at about two-thirds the cost of retraining an entire model. Organizations using risk-tiered routing - where costly human reviews are reserved for high-stakes tasks while low-risk outputs are auto-approved - have reported 40–55% savings in human review costs. Additionally, teams that retrain weekly instead of monthly have achieved 2.1x faster quality improvements.
| Metric Category | Key Performance Indicators |
|---|---|
| Quality | Pass@1, Pass@10, Groundedness >95%, Citation Correctness >90% |
| Operational | Review SLA adherence >97%, Queue wait time, Re-open rate |
| Risk | Incident count, Hallucination rate, Rollback frequency |
| Cost | Cost per reviewed item, Annotation spend vs. value uplift |
These metrics underscore how feedback loops can deliver measurable improvements across quality, operations, risk management, and cost efficiency. But achieving these outcomes requires a disciplined, collaborative approach.
Best Practices for Effective Feedback Loops
To unlock the potential of feedback loops, teams need to combine technical skills with domain expertise. Collaborate across functions. For example, Braintrust’s growth and design teams worked together to optimize prompts by tagging conversations and analyzing metadata. They discovered a 50% satisfaction drop when multiple prompts were used. By introducing a choice prompt, satisfaction scores jumped from 2.1 to 4.3. This success came from blending behavioral insights with technical solutions.
Use structured frameworks for prompts. Proven methods like CO-STAR (Context, Objective, Style, Tone, Audience, Response) and "constraint sandwiches" help define task parameters clearly. Including 30–50 lines of high-quality examples ensures that expectations are well-communicated.
Manage prompts like you would code. Tools like PromptOT allow teams to track changes, run A/B tests, and maintain a detailed changelog to identify which prompt versions drive better outcomes. Version control enables quick rollbacks if a new iteration underperforms. Additionally, environment-specific API keys ensure experimental prompts remain in development until thoroughly tested. Tagging everything - prompt version, model version, user ID, and task type - enables precise regression analysis, ensuring no detail is overlooked.
Challenges and Solutions in Feedback Loop Implementation
Feedback loops are crucial for driving improvements, but they come with their own set of hurdles that demand careful handling.
Common Pitfalls in Feedback Loops
Feedback loops can falter when certain pitfalls are overlooked. One major issue is data overload - collecting too much feedback without a clear method to filter out the noise can lead to delays in decision-making. Another challenge is label drift, where inconsistent human labeling, often caused by unclear guidelines, ends up degrading datasets. Instead of improving prompts, this inconsistency can lower their quality.
Feedback black holes are another problem, occurring when collected data isn’t effectively tied to prompt updates. Without a clear process to connect feedback to action, the data becomes useless. Then there’s reviewer fatigue, which arises as manual review queues grow longer, leading to a drop in annotation quality. Silent regressions are also a concern - this happens when prompt quality deteriorates quietly during model updates or as input patterns shift.
Another issue is the limitation of a single satisfaction rating. It doesn’t identify which specific part of a process - like a tool call or reasoning step - requires adjustment, making it hard to pinpoint areas for improvement. For example, in a study involving 1,401 participants, researchers observed that humans changed their responses 32.72% of the time when an AI disagreed with them, compared to just 11.27% when a human disagreed.
Effectively addressing these pitfalls is essential to keep feedback loops functioning as intended.
Research-Backed Solutions
To overcome these challenges, certain strategies have proven effective. Risk-tiered routing and structured retraining cycles are two standout approaches. Instead of manually reviewing every output, teams can classify responses into low-, medium-, and high-risk categories. Low-risk tasks can be auto-approved, while high-risk cases are reserved for human review. This approach has been shown to reduce review costs by 40–55% without compromising quality. Additionally, teams that adopt structured weekly retraining cycles based on feedback see quality improvements 2.1x faster compared to those using monthly cycles.
To combat label drift, clear rubrics and service-level agreements (SLAs) are key. For instance, setting specific turnaround goals - like completing live support reviews in under two minutes - helps keep review queues manageable. Establishing 5–7 evaluation criteria (such as accuracy, tone, and SEO alignment) ensures consistent output ratings across the team.
When dealing with conflicting feedback, it’s better to look at trends across multiple cases rather than relying on isolated opinions. As Travis Kroon succinctly puts it:
"Aggregate across dozens of cases. Trends beat opinions."
Platforms like PromptOT offer tools to address these challenges. Features such as built-in version control, role-based access, and environment-specific API keys ensure that prompts remain in development until thoroughly tested. This prevents untested changes from reaching production. Instant rollback capabilities allow teams to revert quickly if a new prompt underperforms, while webhook notifications with HMAC-signed payloads create a detailed audit trail. These features ensure that every change is logged and traceable, effectively eliminating feedback black holes.
Conclusion
Feedback loops elevate prompt engineering from a trial-and-error process to a disciplined practice. They help identify silent regressions during model updates, uncover gaps in prompt logic, and allow teams to refine AI outputs based on actual usage patterns. In fact, teams that implement weekly retraining cycles report up to 2.1x faster quality improvements, with structured feedback making prompts as much as 3x more effective.
The real challenge lies in turning observations into actionable steps. As Travis Kroon explains:
"Prompt quality decays over time due to: Model updates, Input distribution shifts, Prompt edits. Feedback loops catch silent regressions, reveal blind spots, and power continuous improvement".
This process requires more than just gathering data. It calls for clear evaluation rubrics, consistent criteria, and a systematic approach to refining prompts.
Collaboration further magnifies these benefits. When growth teams, designers, and engineers analyze logs together, they can identify patterns that might go unnoticed by individuals working in isolation.
To make these collaborative efforts sustainable, robust tools are a must. Features like version control, structured review workflows, and environment-specific testing make scaling collaboration possible. For example, PromptOT addresses common feedback loop challenges with features like draft/published states to prevent untested changes from going live, instant rollback options to recover from regressions, and webhook notifications that maintain audit trails. These tools ensure feedback directly improves prompts.
The takeaway? Feedback loops are essential for production AI. They distinguish between prompts that deteriorate over time and systems that evolve based on user interactions. Incorporating these capabilities ensures every piece of feedback contributes to continuously refining prompt performance.
FAQs
What should I log in a prompt feedback loop?
To refine and improve prompts, it’s essential to log critical data points. This includes details like the prompt version, input provided, model output, and important metadata such as the user ID, timestamp, and model specifications. Collecting this data creates a foundation for understanding how prompts perform in various scenarios.
Feedback is another crucial piece of the puzzle. Whether it comes from human reviewers or automated evaluation tools, feedback or scoring data offers valuable insights into what’s working and what isn’t. Beyond direct feedback, behavioral signals - like token usage, retry rates, and task abandonment - can reveal hidden issues with prompts or outputs.
Flagging problematic responses is also a powerful way to pinpoint and address specific shortcomings. By analyzing flagged outputs, you can uncover patterns and make targeted adjustments to improve future interactions.
Comprehensive logging of all these elements enables ongoing analysis and refinement, paving the way for smarter, more effective prompts over time.
How do I decide which AI outputs need human review?
When determining which AI outputs require human oversight, focus on spotting errors, edge cases, or safety concerns. Pay close attention to outputs that could be inaccurate, pose risks, or potentially violate policies.
To manage this effectively, implement structured processes. Use clear rubrics and set service-level agreements (SLAs) to assess and flag problematic responses. This approach ensures that critical issues are handled properly while keeping quality and compliance standards intact.
How can I prevent silent regressions when models change?
To avoid silent regressions, it's crucial to set up feedback loops that actively monitor how well your model performs. This can involve gathering various types of feedback, such as:
- User input: Direct responses or corrections from users.
- Auto-evaluations: Automated assessments of output accuracy.
- Behavioral signals: Indicators like retry rates or unusual usage patterns.
Automated systems play a big role here. They can log details like prompt versions, user interactions, and performance trends, helping to spot any regressions quickly. Additionally, regular reviews - whether through audits, human evaluations, or auto-labeling - are essential to ensure that updates don’t unintentionally create new problems.
By sticking to a structured feedback process, you can keep your prompts consistent and reliable, even as your model evolves.