
Typed Block Versioning for Scalable AI Prompts
Treat prompts like releases: version typed blocks (role, context, instructions, guardrails, output) for quick rollback and auditable safety.
Read moreBrowse all articles in the prompt engineering category.
Treat prompts like releases: version typed blocks (role, context, instructions, guardrails, output) for quick rollback and auditable safety.
Read more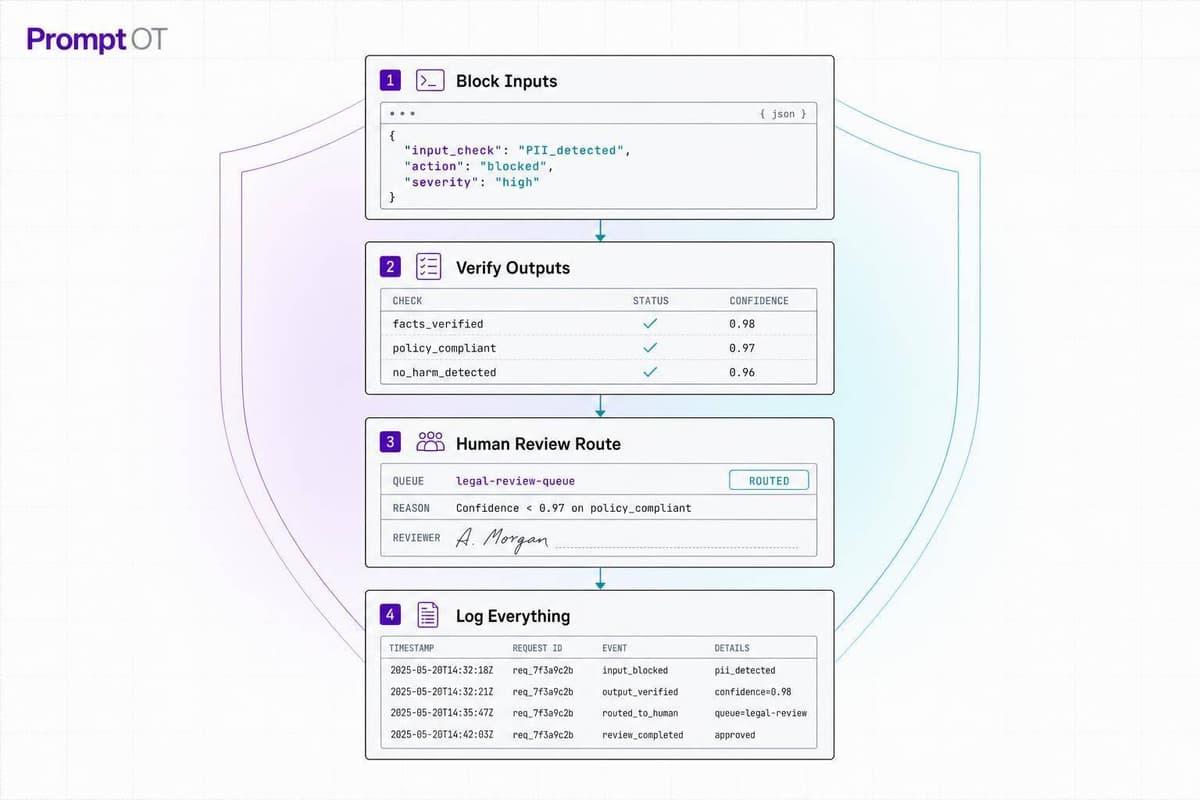
Runtime controls — not policies — make legal AI defensible: block inputs, verify outputs, route to human review, and log everything.
Read more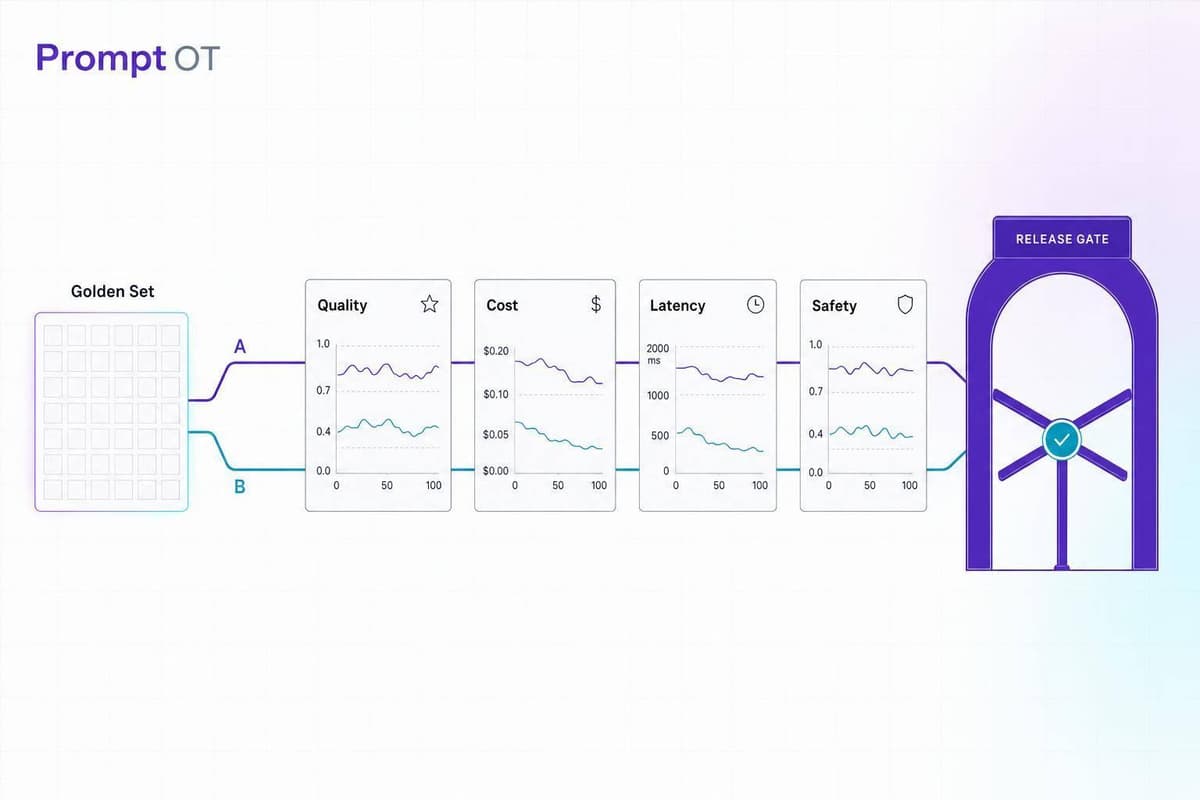
Test prompts on a golden set with 3–5 metrics (quality, cost, latency, safety), use paired tests or A/B, and enforce release gates before shipping.
Read more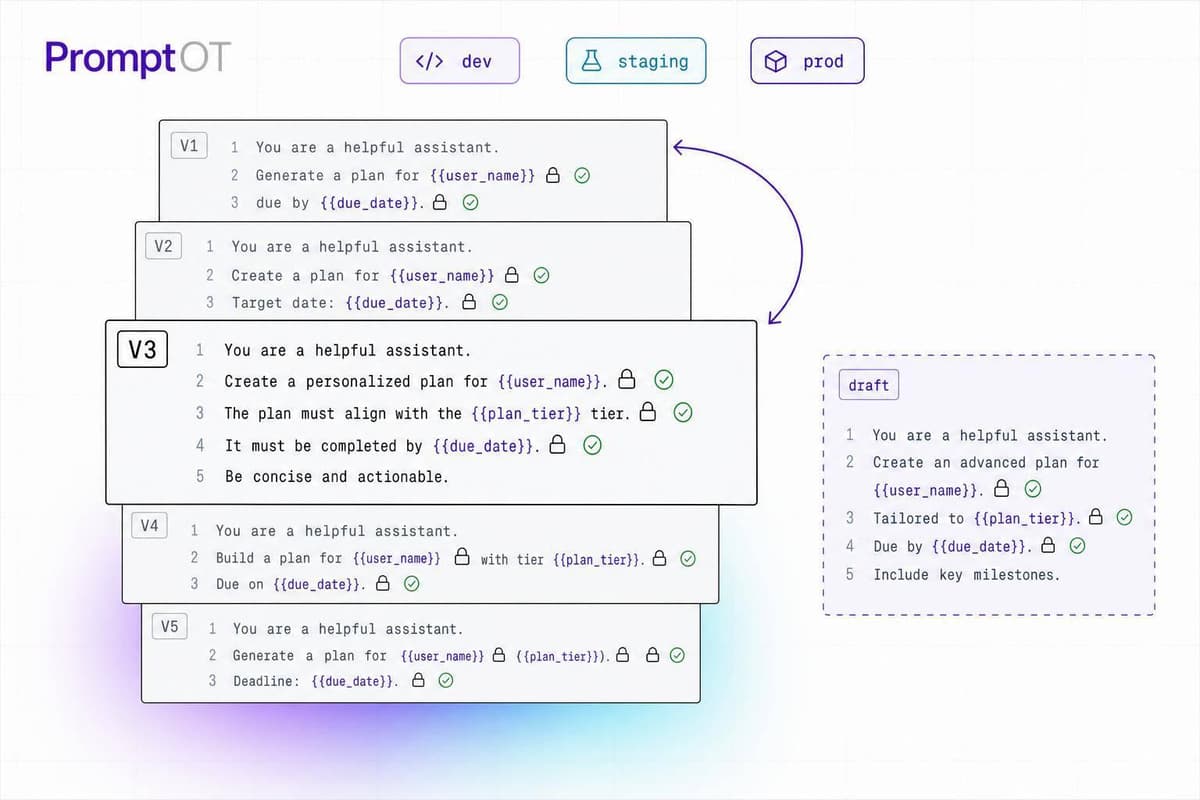
Treat prompts as versioned config: lock variable contracts, validate inputs, separate drafts, check envs, and enable rollback.
Read more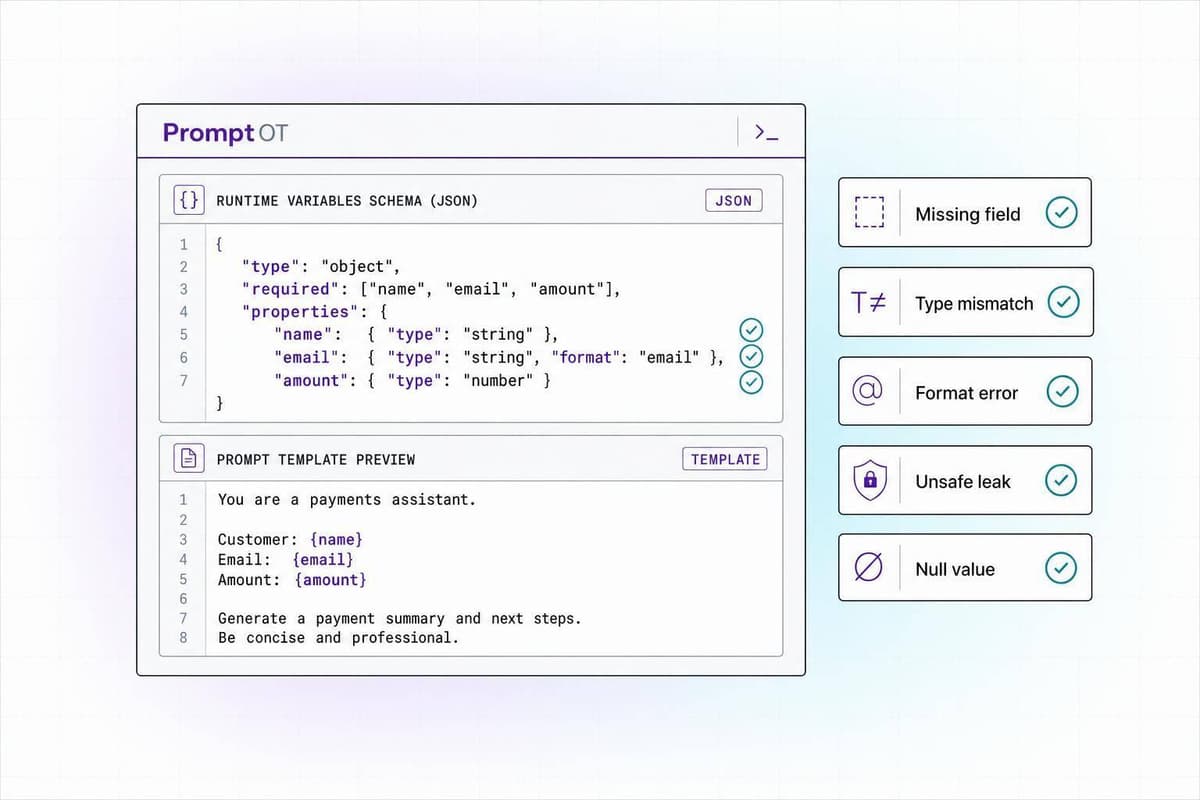
Treat runtime prompt variables like typed, validated inputs to avoid missing fields, leaks, and formatting errors.
Read more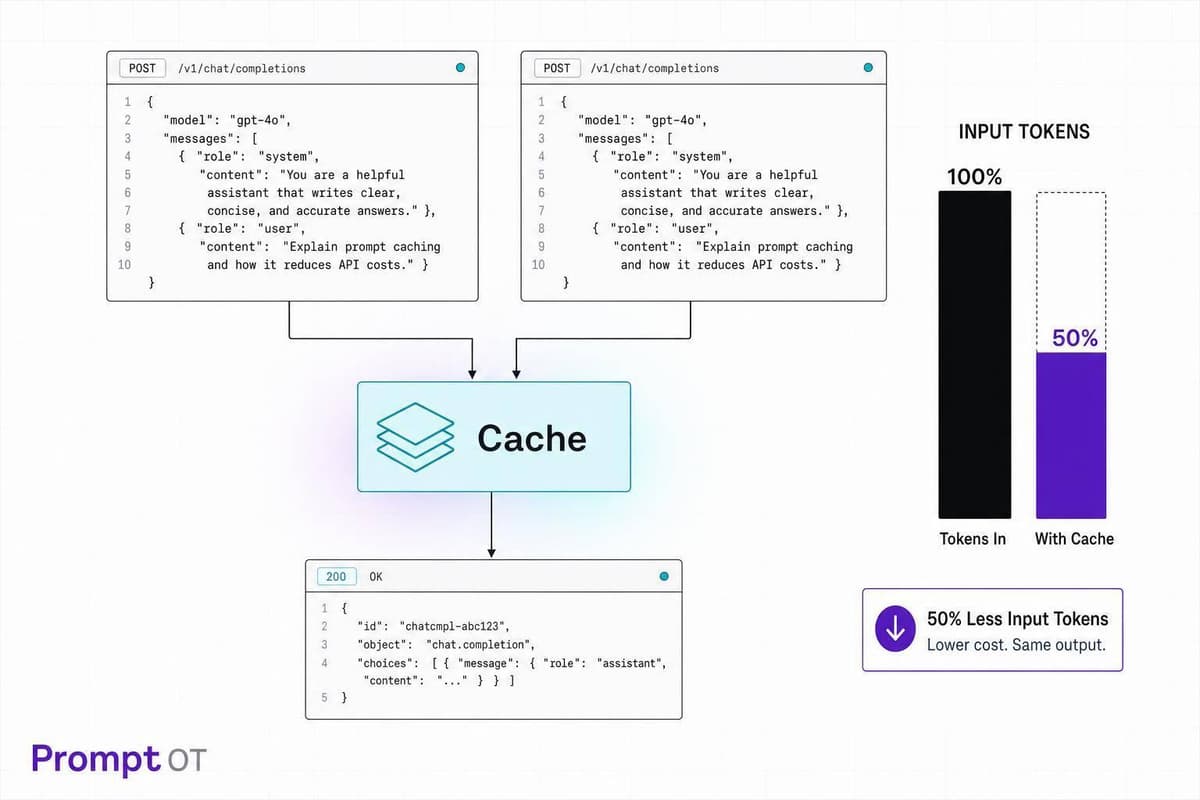
Keep prompt fronts identical to cut LLM API costs and latency—provider and app caching can halve input spend.
Read more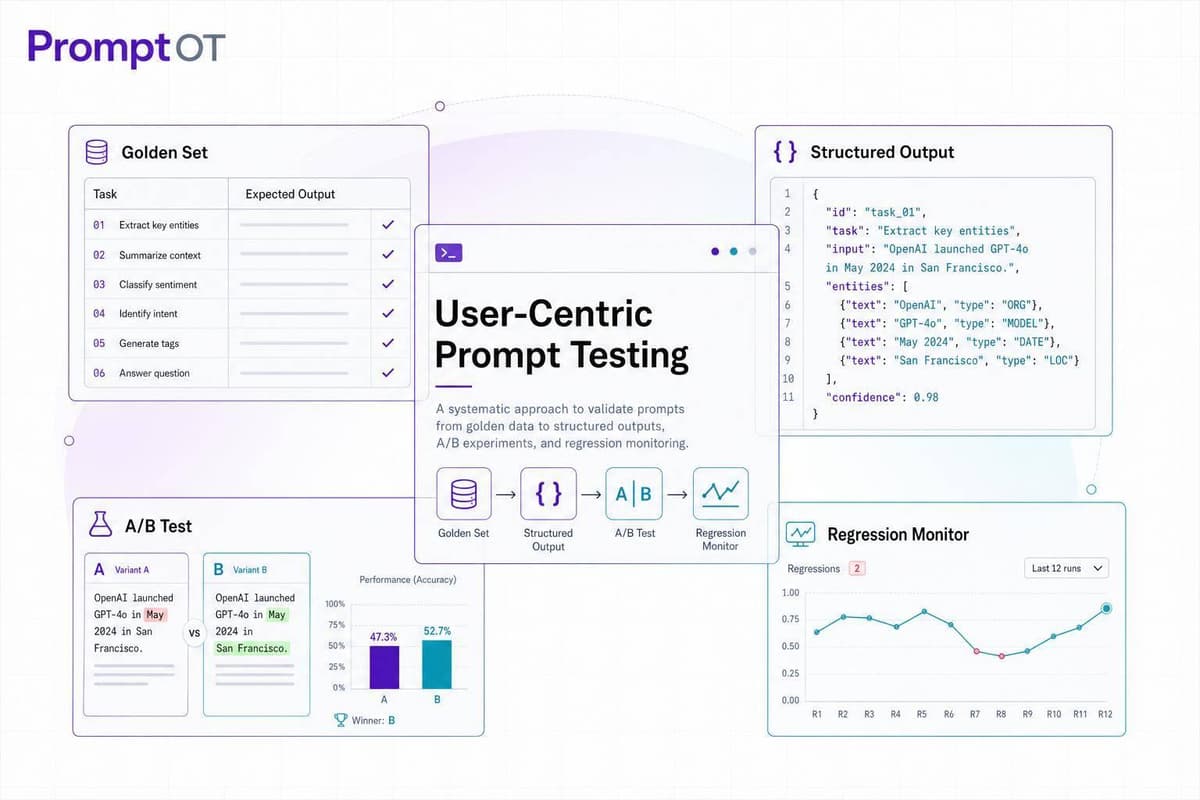
Test prompts against real user tasks: build a golden set, use structured outputs, run controlled A/B tests, and monitor regressions.
Read more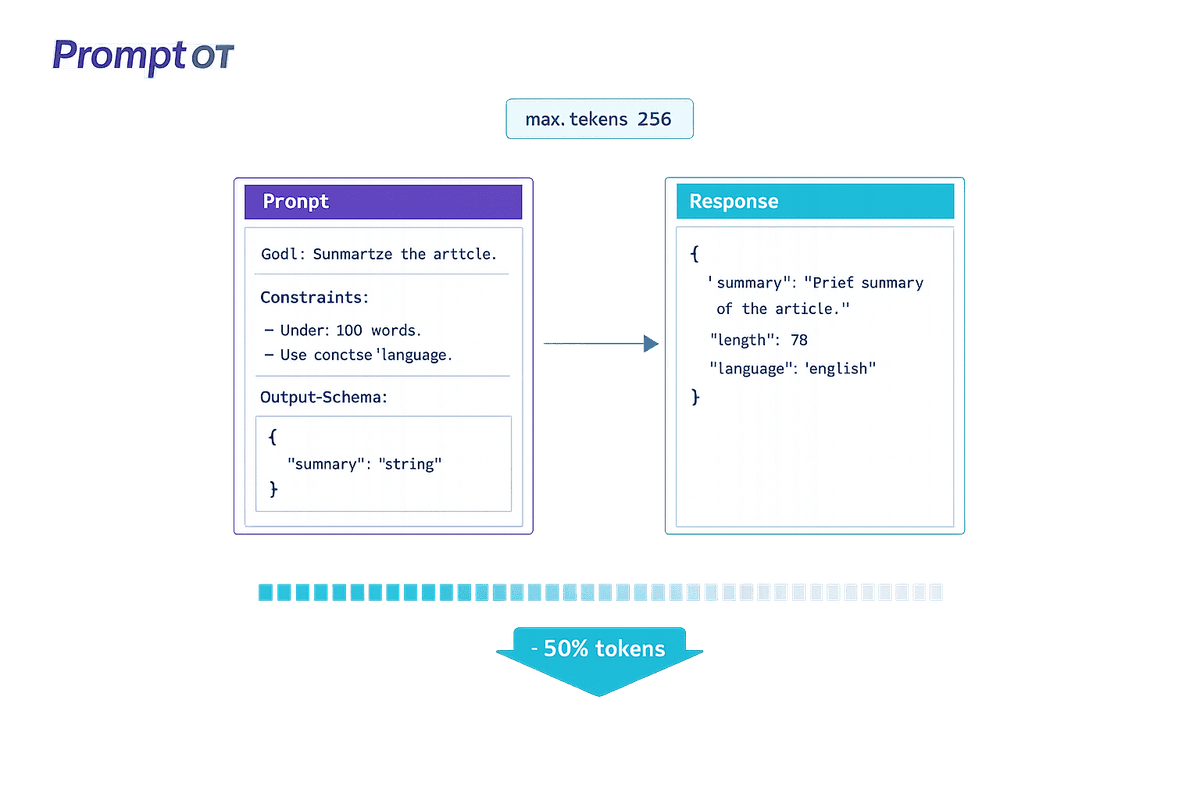
Cut LLM API costs by 40–60% with concise, structured prompts—use delimiters, JSON/YAML, split tasks, set max_tokens, and iterate tests to reduce retries.
Read more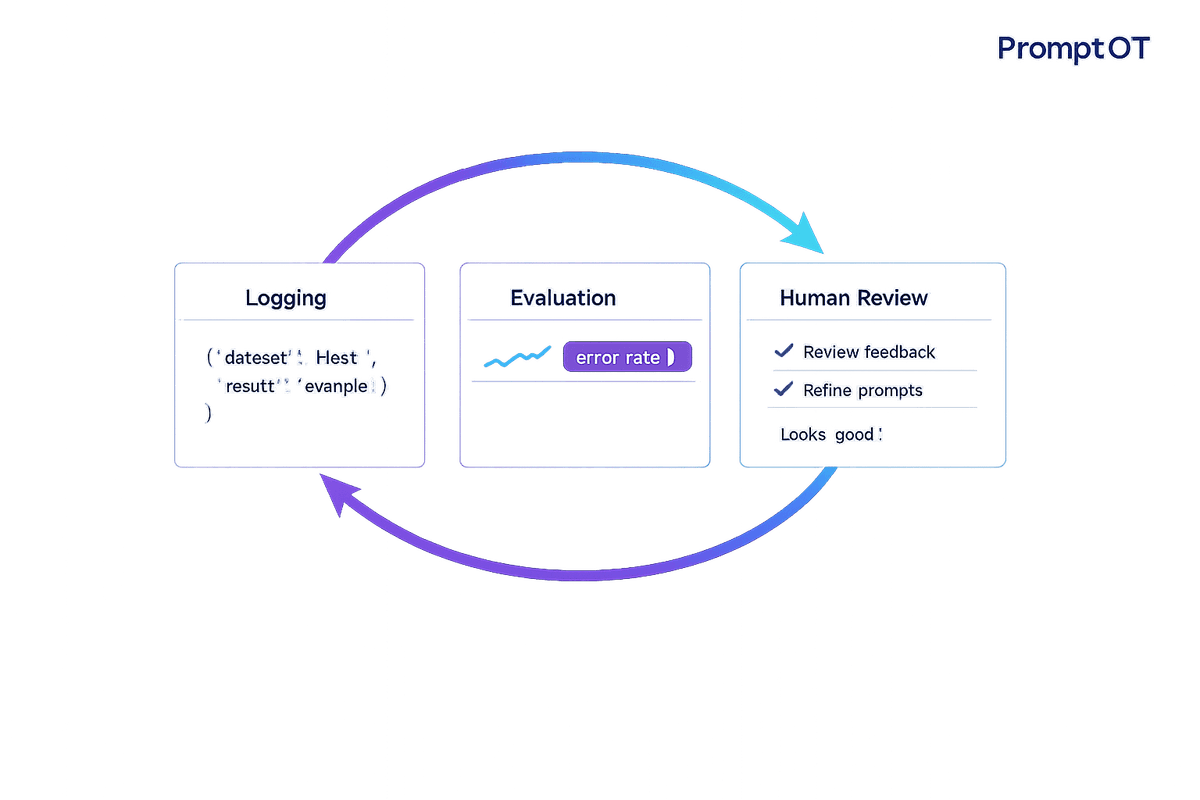
Systematic feedback loops—logging, evaluation, and human review—refine prompts to reduce errors, cut review costs, and accelerate quality improvements.
Read more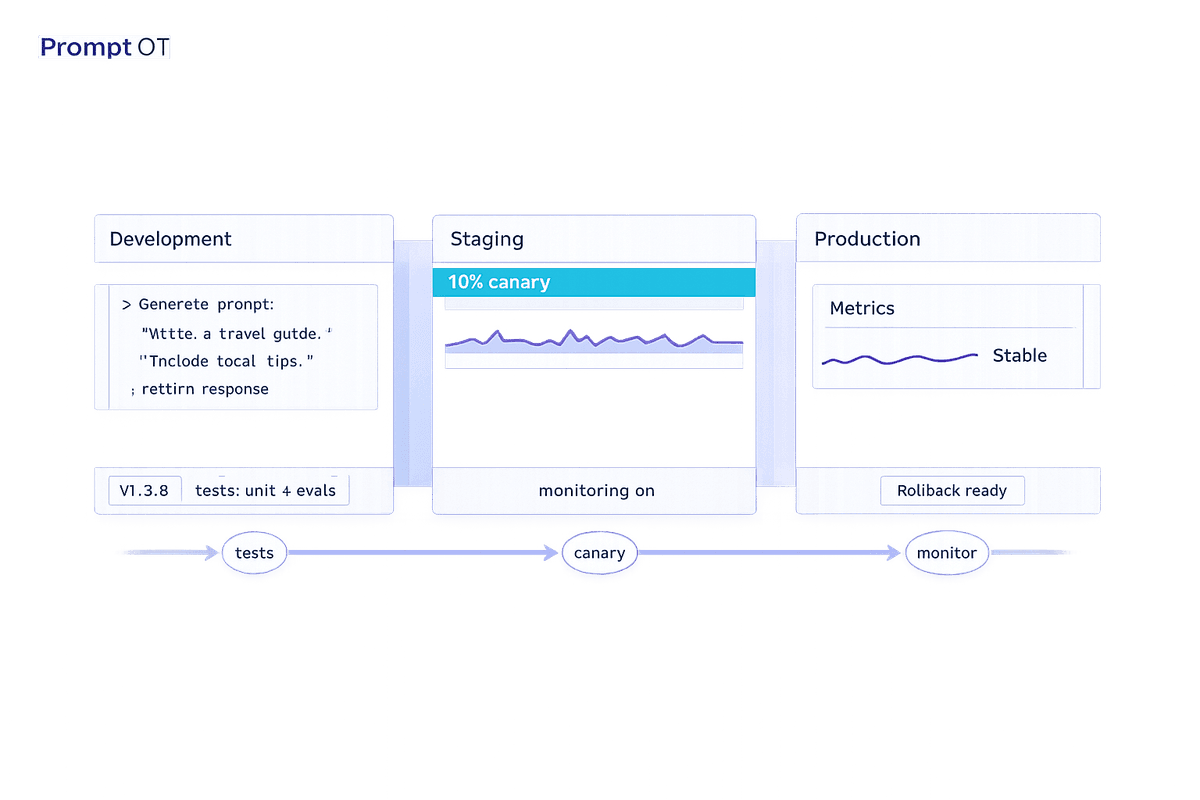
Treat prompts like code: apply semantic versioning, env-specific deployments, automated tests, canary rollouts, monitoring, and fast rollbacks to keep LLMs reliable.
Read more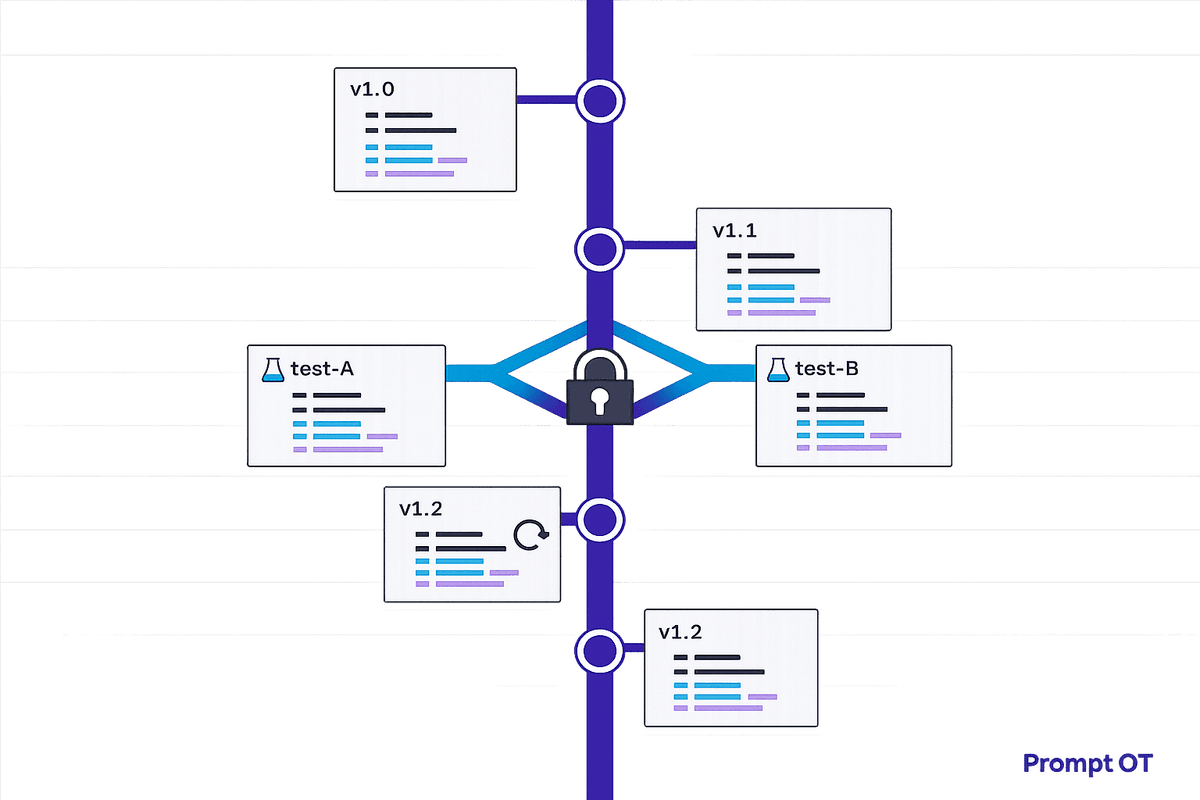
Track every prompt change, prevent silent overwrites, enable safe testing, and rollback instantly with centralized prompt versioning for stable AI production.
Read more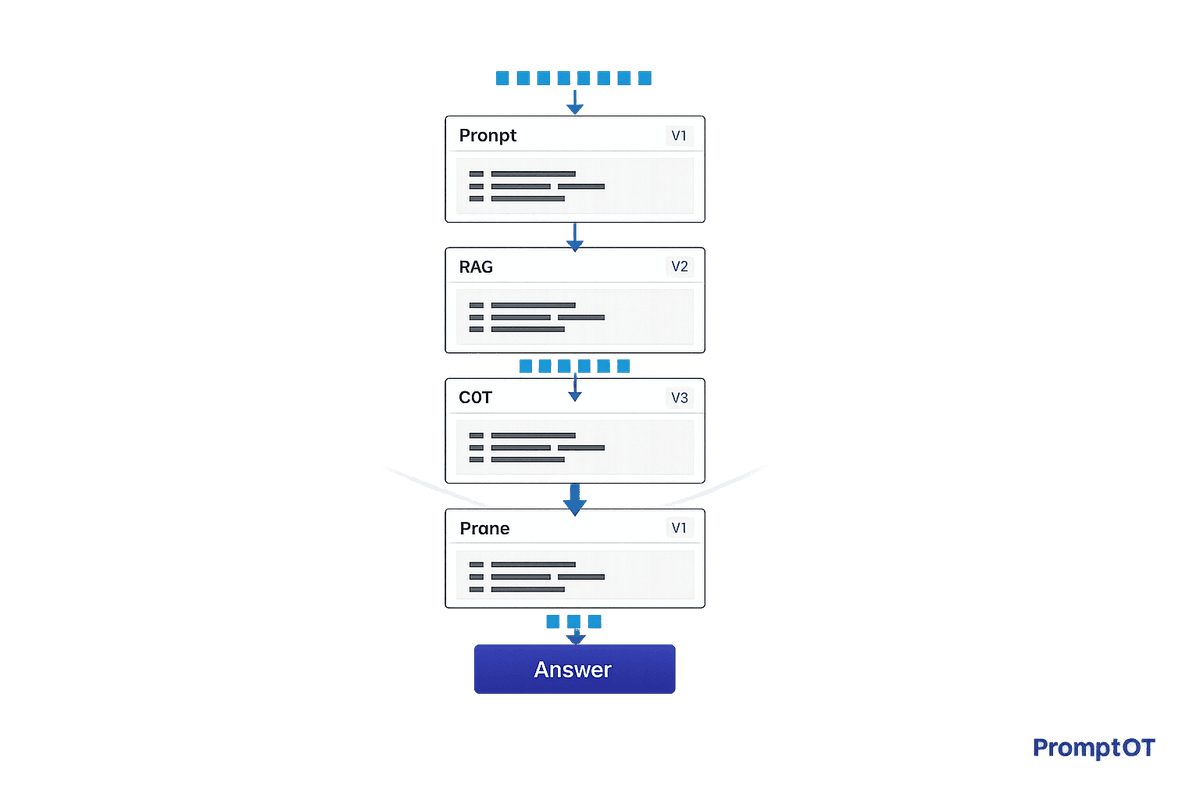
Structure prompts, RAG, CoT scaffolding, and pruning to cut hallucinations, lower token costs, and scale reliable AI team workflows.
Read more