Want better AI performance? It’s not just about prompts anymore - context structuring is the key. This means organizing everything the AI processes, like instructions, data, and conversation history, to avoid errors like hallucinations and inefficiency. Here’s what you need to know:
- Role-Task-Context (RTC): Breaks prompts into clear parts (role, task, context) for precision. Cuts token usage by 20–40% but struggles with long conversations.
- Chain-of-Thought (CoT) with Scaffolding: Improves reasoning by breaking tasks into steps. Reduces errors but uses more tokens and time.
- Dynamic Retrieval-Augmented Context (RAG): Pulls in only the most relevant data. Balances efficiency and accuracy, ideal for large datasets.
- Pruning and Forking: Cleans up conversation history to save tokens and keep focus. Works well for long sessions but risks losing subtle details.
Each method has trade-offs in efficiency, scalability, and error reduction. Tools like PromptOT help manage these patterns with features like reusable prompts, version control, and caching to cut costs by up to 90%.
Bottom line: Structuring context properly can boost AI reliability and scalability while reducing costs.
Context Engineering: Structuring LLM Prompts
sbb-itb-b6d32c9
1. Role-Task-Context Pattern
The Role-Task-Context (RTC) pattern offers a structured way to eliminate ambiguity in AI prompts. By breaking prompts into clear components, it ensures precision and reduces guesswork. Here's how it works: Role defines the AI's identity (e.g., "B2B SaaS marketing strategist"), Task specifies the action with clear verbs (like analyze, create, or summarize), and Context provides the background information needed to shape the response. Many teams expand this into the RTCCO framework, adding Constraints and Output guidelines for even more clarity.
This method works because it simplifies communication. Instead of leaving the AI to interpret vague instructions, each component delivers clear and actionable guidance. As Anthropic explains:
Good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome.
This approach not only makes prompts more efficient but also brings measurable benefits in areas like token usage, team collaboration, error reduction, and scalability.
Token Efficiency
By clearly defining the role and task, the RTC pattern avoids wasting tokens on irrelevant or off-topic responses. This keeps prompts concise and focused. For example, structured prompts prevent the model from generating unnecessary content, leading to tighter, more relevant outputs. Research shows that prompts optimized for token efficiency can maintain 95% effectiveness while using 40% fewer tokens compared to less structured alternatives.
Team Collaboration Suitability
The RTCCO framework acts as a reusable "prompt skeleton" that teams can adapt across different projects. This standardization ensures consistent communication. For instance, terms like "qualified lead" or "critical component" carry the same meaning across teams, reducing the need for follow-up questions by 85% and significantly cutting down on iteration cycles. In June 2025, a healthcare provider achieved a 60% reduction in proposal iteration time during a system refactor by embedding metadata like Component: PatientRecordsService and Compliance: HIPAA into their prompts.
Error Mitigation
Explicitly defining roles and constraints helps narrow the AI's focus, reducing errors like hallucinations or off-brand responses. Breaking down complex tasks into smaller parts improves accuracy by 35% on average. For example, in September 2024, a B2B SaaS company used a structured RTCCO prompt to analyze a Q3 demand generation campaign. With a $25,000 budget and 118 leads at $212 cost-per-lead, they set constraints for a Q4 budget of $30,000 and an $85 CPL target. This led the AI to deliver a targeted 30-day action plan without generic or irrelevant suggestions.
Scalability
The RTC pattern ensures prompts remain effective, even as use cases grow. By including all necessary details within the prompt itself, it avoids reliance on prior conversation history, making it ideal for extended interactions. This self-contained approach guarantees consistent performance as organizations scale AI across various applications and models.
2. Chain-of-Thought with Contextual Scaffolding Pattern
The Chain-of-Thought (CoT) with Contextual Scaffolding pattern helps AI tackle complex problems by breaking them into clear, logical steps. Instead of jumping straight to conclusions, the model outlines its reasoning process, leading to a 30-50% improvement in accuracy for intricate tasks. This method shifts AI from being a "probabilistic guesser" to functioning as a "systematic analytical tool".
Scaffolding adds structure to this reasoning process by using frameworks to set boundaries. Shoeb Ali, in Orchestrating Agentic AI, highlights this point:
The difference between an LLM that occasionally impresses and one that consistently delivers is not the model - it is the specification you give it.
This approach tackles a common issue: 61% of developers report that AI often generates code that appears correct but isn’t reliable. By requiring step-by-step reasoning and anchoring it to clear constraints, this method reduces errors like hallucinations, which occur when models combine multiple steps into a single leap. This structured reasoning also improves efficiency and teamwork.
Token Efficiency
The CoT pattern, with its structured reasoning, is particularly useful for tackling multi-step problems. However, it requires more resources, using 2-5 times more tokens than direct prompting and increasing response times by 35-600%. To manage these costs, teams should reserve CoT for tasks like debugging, multi-step reasoning, or intricate planning.
A practical example comes from January 2026, when researcher Mariya Mansurova applied the Agentic Context Engineering (ACE) framework to a PolyAI banking dataset with 77 intent categories. By using a Generator-Reflector-Curator loop, the system achieved a 10.6% performance boost while slashing token costs by 83.6% compared to traditional methods. Teams can also reduce costs by caching static prompts, like system instructions, which can cut expenses by up to 90% and lower latency by 85%.
Team Collaboration Suitability
Structured scaffolding fosters better teamwork by creating a shared framework for reasoning. Few-shot CoT examples serve as templates, teaching the model the specific logic and standards your team follows. Using XML tags like <rules>, <context>, and <examples> ensures outputs are both predictable and machine-readable, which is crucial for production-scale workflows.
Version control is another important element here. Storing prompts in a shared repository prevents "context rot", where uncoordinated adjustments by team members degrade the system's reliability over time.
Error Mitigation
Scaffolding also helps address issues like the "Lost in the Middle" effect, where information buried in the middle of a context window can lose accuracy by over 30%. Placing critical instructions at the start or end of a prompt ensures they receive maximum attention. Teams can also implement verification gates - additional prompts that check outputs against specific criteria before moving forward.
This approach, paired with positive framing (e.g., rephrasing "don’t use mock data" as "only use real data"), minimizes errors. Few-shot examples further reduce formatting mistakes by 60-80%, while only adding 200-300 tokens to the process.
Scalability
For larger applications, rewriting entire prompts is inefficient. Instead, teams can use "delta" updates to modify structured playbooks without losing critical knowledge - a problem known as "context collapse". This method allows dynamic updates to reasoning chains while keeping the overall structure intact.
As Andrej Karpathy puts it:
The LLM is a CPU, the context window is RAM, and your job is to be the operating system, loading working memory with exactly the right code and data for each task.
This architectural approach shifts the focus from crafting individual prompts to designing an efficient information pipeline. By combining dynamic updates with earlier models, teams can ensure consistent performance across a wide range of tasks and applications.
3. Dynamic Retrieval-Augmented Context Pattern
The Dynamic Retrieval-Augmented Context (RAG) pattern addresses a key issue: how to provide AI with current, relevant information without overloading its attention span. Instead of dumping entire datasets or files into a prompt, this method pulls in just the most relevant pieces as needed. The result? A system that stays grounded in real-world data without suffering from the performance drop that comes with bloated context windows.
A study of 13 leading models revealed that 11 of them experienced a 50% performance drop at just 32,000 tokens - well below their advertised limits. Traditional prompt engineering often falls short, with 73% of production integrations failing because 4,000-8,000 token windows can’t capture essential dependencies. Dynamic RAG solves this by treating the context window as a limited resource, allocating tokens with precision instead of indiscriminately.
Token Efficiency
Dynamic retrieval operates on a straightforward principle: retrieve only what’s necessary. For example, instead of including all 2,200 lines of code, the system pulls just the 90 lines that are crucial. This "pull-based" method uses tool calls to fetch specific data only when required, significantly reducing initial token usage.
When retrieval occurs, weighted truncation ensures that the most relevant documents get priority. Token budgets are distributed based on relevance scores, so critical content isn’t overshadowed. Teams can also employ tiered compression: raw context below 80% capacity, stripped filler at 85%, and summarized older turns when nearing 90%+ . This approach prevents attention from degrading before the context window is full.
Another efficiency boost comes from prefix caching. By keeping stable instructions and tool definitions unchanged, teams can save up to 90% on cached input tokens with API providers . Since tool definitions and responses often make up 80% of total tokens in production prompts, this optimization can significantly reduce costs and latency. These strategies not only streamline processes but also foster better collaboration.
Team Collaboration Suitability
Dynamic RAG also enhances teamwork by modularizing context. Using XML tags like <identity>, <tools>, and <sources> allows different team members to edit and manage specific sections of a prompt without stepping on each other’s toes. This structure helps avoid the chaotic "Frankenstein prompts" that result from uncoordinated updates.
Another advantage is the inclusion of verifiable citations. By using structured formats like [source_id], every claim made by the AI can be traced back to its source. This audit trail is crucial in production environments where accountability is key. Treating prompts like code - with version control, diffs, and rollback - also prevents fragile, monolithic structures.
Error Mitigation
Dynamic RAG addresses several common errors in static context systems. One is the "lost in the middle" effect, which can lower accuracy by 20%. The solution? A sandwich pattern that places the most relevant documents at the beginning and end of the context window, where attention is strongest.
To reduce hallucinations, grounding instructions establish a "Context-Task Contract", ensuring the model prioritizes retrieved information over its internal training data . Implementing refusal logic - where the model says, "I don’t have enough information" when retrieval fails - further minimizes guesswork .
Dynamic RAG also combats context poisoning, where errors in the context compound over time. By validating information before adding it to long-term memory, the system prevents bad data from contaminating future interactions. This validation acts like a safeguard, ensuring data integrity.
Scalability
Dynamic RAG uses hierarchical summarization to balance detail with coverage. Long texts are summarized independently, and these summaries are used as context, enabling broader analysis without exceeding token limits. Agent isolation takes this further by dividing complex tasks among multiple agents, each with its own focused context window, rather than overloading a single orchestrator .
To enhance precision, hybrid retrieval combines semantic vector search with keyword search (BM25). This ensures that rare terms, IDs, and specific code snippets aren’t missed, improving tool selection accuracy from 13.6% to 43.1% .
Scalability is a real challenge. Including unnecessary repository context files can reduce agent success rates and increase inference costs by more than 20%. As Anthropic advises, the goal is to "find the smallest set of high-signal tokens that maximize the likelihood of your desired outcome". This mindset separates scalable systems from those that crumble under excess data.
4. Conversation History Pruning and Forking Pattern
Managing long conversation histories in AI systems can feel like trying to navigate a cluttered attic. Over time, failed attempts and filler messages pile up, hogging the context window and making it harder to focus on what really matters. The Conversation History Pruning and Forking pattern addresses this by actively curating the conversation history - keeping what’s useful and clearing out the rest. Think of it as treating conversation history like a limited resource, not an endless archive. This approach ensures efficient token usage while maintaining clarity.
Token Efficiency
Pruning is all about cutting out the fluff while preserving the core. By removing low-value messages, context size can shrink by 30–40%, leaving only the essentials. A technique called "turn compression" takes this a step further - turning a 300-token detailed explanation into a concise 15-token summary. This keeps the signal clear without losing important information.
Forking, on the other hand, separates tasks into their own context windows. A lead agent oversees the big picture while sub-agents focus on specific tasks in isolation. Once their work is done, they return with concise summaries - usually around 1,000–2,000 tokens. As Andrej Karpathy aptly put it:
Context is the programming now - get the right information into the window for the next step.
Team Collaboration Suitability
This pattern doesn’t just work for AI; it mirrors how effective teams operate. A lead agent handles the overarching plan, while specialized sub-agents dive into technical tasks without cluttering the main thread. Keeping a Decision Log - a record of resolved decisions and their reasoning - prevents the AI from rehashing settled issues. Clear precedence rules, where the current task brief overrides older conflicting data, ensure everyone stays on the same page. This is critical because research on over 1,600 multi-agent system failures found that 36.9% stemmed from misalignment between agents.
Error Mitigation
Messy trial-and-error loops can pollute the context, degrading quality over time. Once the context becomes "poisoned", recovery is nearly impossible without starting fresh. As Hacker News contributor Benjammer explained:
once your context is 'poisoned' it will not recover, you need to start fresh with a new chat.
Pruning helps by filtering out low-quality data, ensuring only the best information remains in the reasoning process.
However, overly aggressive pruning can backfire, discarding subtle but important details. A balanced approach, like rolling summarization, works better. This involves keeping the last 3–5 messages verbatim while summarizing older content into a concise format. This method retains essential context without dragging along unnecessary baggage, preventing critical details from getting buried.
Scalability
When it comes to scaling, pruning and forking can slash costs by up to 80% while still delivering high-quality responses. For tasks that stretch over hours or involve thousands of steps, structured note-taking allows agents to store key information outside the context window altogether. Features like resumeSessionAt make it possible to reuse internal states - like messages, tools, or prompt caches - without replaying the entire conversation history. This avoids token waste and the risk of inconsistent or redundant outputs. As the Anthropic Engineering Team puts it:
finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome.
Pros and Cons Comparison
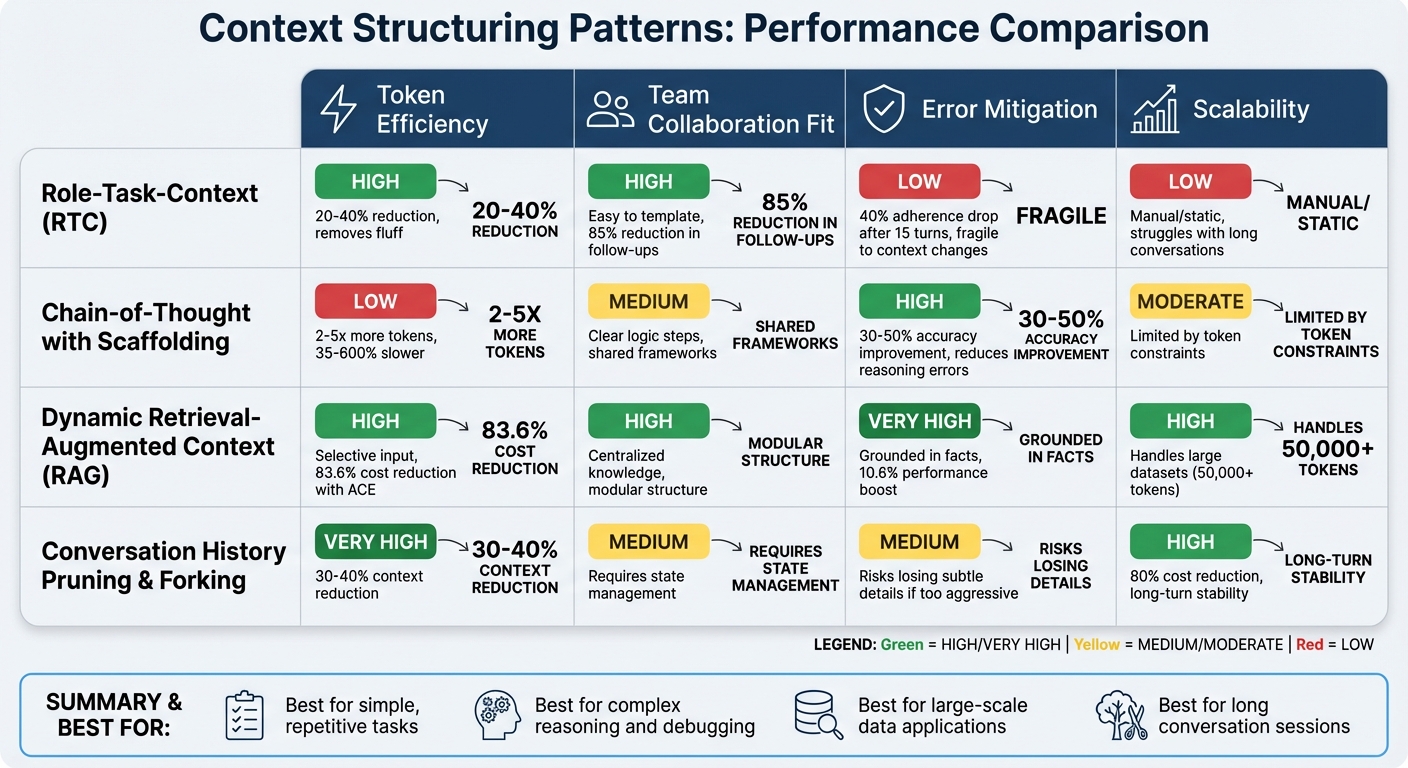
Context Structuring Patterns for AI: Comparison of Token Efficiency, Collaboration, Error Mitigation, and Scalability
Every pattern comes with its own set of trade-offs. Here's a quick breakdown of the strengths and weaknesses of each, based on the earlier discussions.
The Role-Task-Context pattern stands out for cutting down token usage by 20–40%, as highlighted earlier. Its standardized structure makes teamwork easier, but it struggles when conversations extend or contexts shift. In fact, instruction adherence can drop by 40% after 15 turns in a conversation.
Chain-of-Thought with Scaffolding is great for reducing reasoning errors, which makes it useful for tasks like complex debugging. However, it’s heavy on tokens. As Yash M Gupta, PhD, aptly puts it:
Tokens are the currency of AI. More tokens = higher costs + slower responses.
This method prioritizes precision, but at the expense of efficiency.
Dynamic Retrieval-Augmented Context, on the other hand, balances efficiency and accuracy by retrieving only the most relevant information for each step. It’s scalable and relies on external data, which helps reduce hallucinations. When paired with Agentic Context Engineering (ACE), it slashes token costs by 83.6% compared to baseline methods and boosts AI task performance by 10.6%. However, setting this up requires a solid data infrastructure, which adds complexity.
Conversation History Pruning and Forking works like a memory cleaner, removing unnecessary context to keep costs in check. It’s especially effective for long sessions, but if pruning is too aggressive, important nuances might get lost. Ilia Ilinskii, Founder of Rephrase-it, cautions:
If you treat the context window like a trash drawer where everything goes 'just in case,' you'll eventually get noise, conflicts, and drift.
Here’s a table summarizing the trade-offs across key metrics:
| Pattern | Token Efficiency | Team Collaboration Fit | Error Mitigation | Scalability |
|---|---|---|---|---|
| Role-Task-Context | High (removes fluff) | High (easy to template) | Low (fragile to context changes) | Low (manual/static) |
| Chain-of-Thought with Scaffolding | Low (verbose reasoning) | Medium (clear logic steps) | High (reduces reasoning errors) | Moderate (limited by token limits) |
| Dynamic Retrieval-Augmented Context (ACE) | High (selective input) | High (centralized knowledge) | Very High (grounded in facts) | High (handles large datasets) |
| Pruning & Forking | Very High (removes noise) | Medium (demands state management) | Medium (risks losing subtle details) | High (long-turn stability) |
Tools for Managing Context Structure
Managing context effectively is key to scaling AI systems, and tools like PromptOT are designed to make this process smoother. Handling context at scale requires infrastructure built specifically for the task. As one expert puts it:
Prompt engineering focuses on the words inside a single request. Context engineering shapes everything that surrounds those words.
PromptOT takes a modular approach with block-based composition. It lets teams build prompts using blocks for elements like roles, context, instructions, guardrails, and output formats. These blocks can be rearranged easily with a drag-and-drop interface. To support collaboration, it offers version control with draft and published states, instant rollback, and environment-scoped API keys to separate development from production environments. The platform also supports variable interpolation using {{placeholders}}, which are resolved at runtime. Plus, its LLM-agnostic design ensures compatibility with major providers like OpenAI, Anthropic, and Google.
PromptOT also brings advanced features like reusable prompts, strong version control, and prompt caching. By placing static content at the start of prompts, users can reduce costs and improve latency through caching. Additionally, webhook notifications with HMAC-signed payloads allow for real-time integration monitoring.
As research highlights:
Success in AI implementations hinges on context precision.
With tools like PromptOT, managing this precision becomes much more achievable.
Conclusion
Different context structuring patterns cater to unique needs. Role-Task-Context fits well for straightforward, repetitive tasks where consistency is key. On the other hand, Chain-of-Thought scaffolding is crucial for multi-step reasoning, though it can take significantly longer - anywhere from 35% to 600% more time compared to direct requests. For large-scale tasks involving repositories with over 50,000 tokens, Dynamic Retrieval-Augmented Context becomes indispensable, especially when traditional methods fall short. Meanwhile, Pruning and Forking helps maintain consistency in extended conversations by separating permanent constraints from temporary details.
Simpler patterns may be faster, but more advanced ones excel at handling complexity, even though they come with higher token costs. For teams using GPT-4, it's worth noting that instruction adherence can decline by as much as 40% after 15 conversation turns without proper context management. Additionally, information buried in the middle of the context window can experience an accuracy drop of over 30%.
Optimized context management can significantly enhance AI performance. By structuring and loading only the most essential data into a task's working memory, teams can boost AI productivity by 40–60%. Experts often compare the context window to RAM, emphasizing the importance of managing it like an operating system to ensure the right information is available for each task.
PromptOT's block-based system supports consistent implementation of these patterns. This approach treats prompts as versioned code rather than disposable chat messages, helping teams avoid "prompt drift" when models or requirements evolve. Features like environment-scoped API keys allow teams to test context structures in development before deploying them, while prompt caching can cut costs by up to 90% and reduce latency by 85%. Moving from ad-hoc methods to systematic context engineering is a critical step for achieving reliable AI scalability.
Shifting focus from simple prompt design to advanced context engineering lays the foundation for building scalable and dependable AI systems. A strong infrastructure paired with well-defined patterns is essential for long-term success.
FAQs
Which context pattern should my team start with?
The RTCO (Role–Task–Context–Output) pattern offers a straightforward framework for structuring prompts. By clearly outlining the role, task, context, and expected output, it helps ensure clarity and dependable AI responses.
Using this pattern, your team can craft prompts that are modular and easy to adjust. This approach minimizes errors, maintains consistency, and simplifies the process of scaling or fine-tuning your strategies as needed.
When should we use RAG instead of longer prompts?
When a model needs to access and incorporate external knowledge, Retrieval-Augmented Generation (RAG) is a powerful approach. It ensures the model retrieves and integrates relevant information, helping it focus on accurate and contextually appropriate content. This method reduces the risk of hallucinations - those moments when the model generates incorrect or fabricated details.
Another key point? Longer prompts can be more effective, but only if all the necessary context fits within the model's token limit. By providing comprehensive, relevant information upfront, you guide the model to produce more precise and reliable outputs.
How can we prune chat history without losing key details?
To clean up chat history without losing important details, focus on removing less relevant or repetitive messages while keeping the essential context intact. You can do this by shortening older or unnecessary parts of the conversation and turning long exchanges into brief, clear summaries. Another approach is using retrieval-augmented generation (RAG), which dynamically pulls the needed information, minimizing the need to rely on the entire chat history. These strategies ensure key details are preserved while improving efficiency and managing token usage effectively.