Prompt drift is a silent issue that can disrupt AI systems without any visible changes to code or prompt text. It leads to inconsistent outputs, flawed reasoning, and reduced accuracy over time, often caused by silent model updates, changing input data, or the inherent variability of AI models.
To tackle prompt drift effectively, here’s what you need to know:
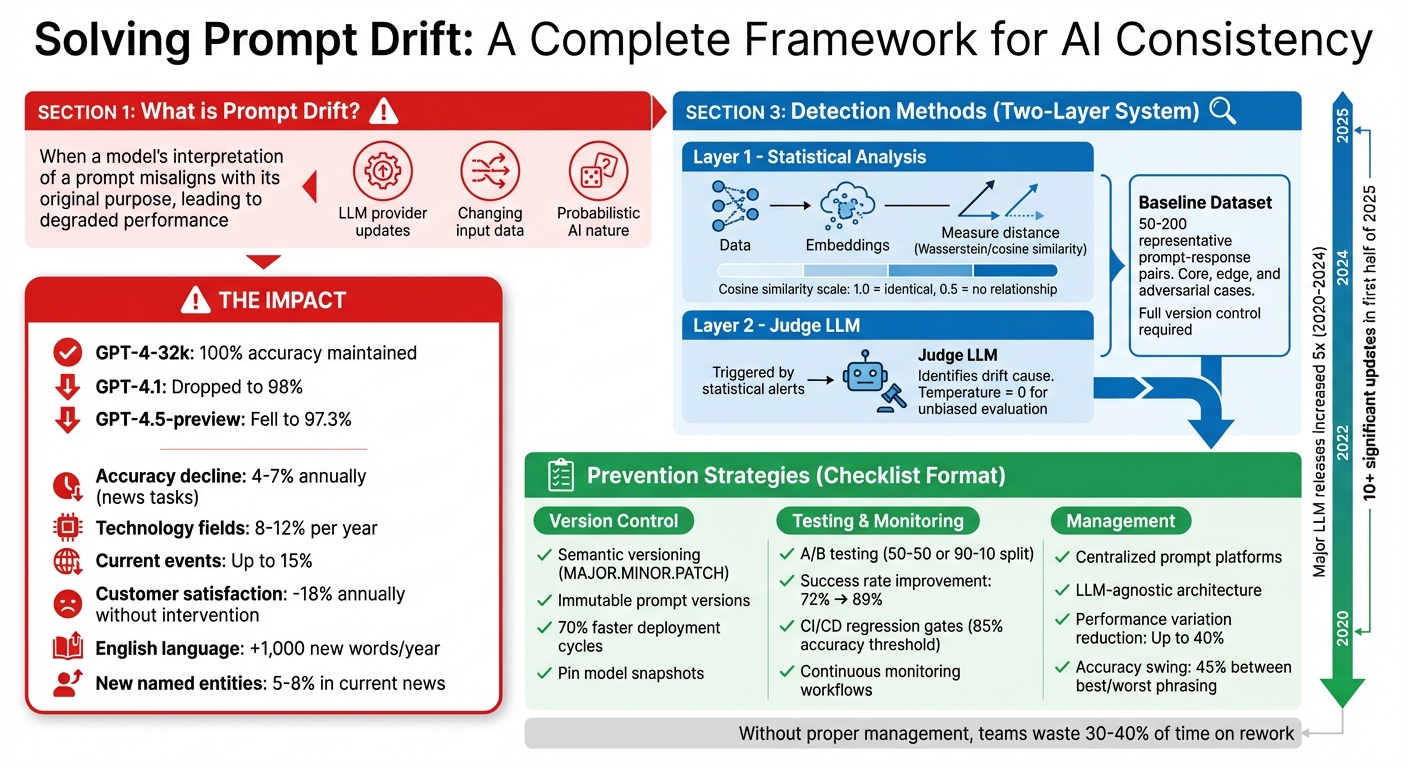
- What is Prompt Drift? It occurs when a model's interpretation of a prompt misaligns with its original purpose, leading to degraded performance.
- Why It Happens: Triggered by LLM provider updates, changes in input data, or the probabilistic nature of AI.
- Impact: Reduced accuracy, cascading errors in multi-agent systems, and increased costs.
- Detection: Use embedding-based semantic analysis and Judge LLMs to monitor statistical and behavioral changes.
- Prevention: Employ version control for prompts, maintain baseline datasets, and implement A/B testing for stability.
- Long-Term Solutions: Use centralized prompt management platforms, continuous monitoring workflows, and LLM-agnostic systems to ensure consistency.
Complete Framework for Detecting and Preventing AI Prompt Drift
Building Trustworthy AI: Avoid Model Drift & Unsafe Outputs
sbb-itb-b6d32c9
What Causes Prompt Drift
Prompt drift stems from several identifiable factors, and understanding these is crucial for creating more stable AI systems.
Model Updates and Version Changes
Large Language Model (LLM) providers frequently release silent updates that include changes like weight adjustments, recalibrations of safety layers, and backend optimizations. These updates can alter how models interpret the same prompt, often leading to drops in accuracy. For instance, a study by Tursio Inc. (June 2024–July 2025) found that while GPT-4-32k maintained 100% accuracy, GPT-4.1 dropped to 98%, and GPT-4.5-preview fell to 97.3%. Specific issues included errors in interpreting SQL fragments and reduced semantic accuracy.
"Existing prompts optimized for other models may not immediately work with this model, because existing instructions are followed more closely and implicit rules are no longer being as strongly inferred." - OpenAI Prompting Guide
The pace of these updates is accelerating. Between 2020 and 2024, major LLM releases increased fivefold, and the first half of 2025 alone saw over 10 significant updates. This rapid evolution often results in "negative flips", where inputs that worked on older versions suddenly fail on newer ones. Some models have even been discontinued with as little as three months' notice, forcing teams to adapt their applications under tight deadlines.
These version changes often set the stage for other drift factors, such as variations in input data and the inherent unpredictability of the models themselves.
Changes in Context and Input Data
External data variability is another major contributor to prompt drift. Real-world production inputs often include unexpected elements like typos, slang, or topics that weren’t part of controlled test data. This leads to "data drift", where the statistical patterns of production inputs shift away from the original training baseline. In retrieval-augmented generation systems, evolving external data sources can introduce language that inadvertently redirects the model, causing "task drift" where outputs stray from the intended purpose.
The English language alone adds about 1,000 new words and phrases every year, and between 5% and 8% of named entities in current news didn’t exist in text corpora from five years ago.
"The prompt hasn't changed; the input data distribution has shifted. The mismatch causes degradation." - Applied AI
State-of-the-art LLMs typically see accuracy decline by 4% to 7% annually on news-related tasks as they move further from their training cutoff. In fast-changing fields like technology, this drop can reach 8% to 12% per year, and for current events, it can climb to as high as 15%. Without proper intervention, some commercial deployments have experienced customer satisfaction scores falling by an average of 18% annually.
Non-Deterministic Model Behavior
Unlike traditional software, LLMs operate probabilistically, meaning their outputs can vary even when given the same input. This variability becomes more pronounced in multi-agent systems, where context and tool usage can shift between runs, increasing the unpredictability of outputs. Even at zero temperature settings - designed to minimize randomness - variations still occur, making single-response checks unreliable.
"Prompts that worked yesterday can fail tomorrow, and nothing in your code changed." - Statsig
This unpredictability poses significant challenges, especially in agentic loops. Without careful monitoring, drift in these systems can lead to infinite re-planning cycles, causing token costs to skyrocket from hundreds to thousands of dollars in a short period. Addressing this variability is critical for maintaining system reliability over time.
How to Detect and Monitor Prompt Drift
Prompt drift occurs when there’s a shift in the inputs your system receives - like changes in user behavior, new edge cases, or evolving query patterns. This contrasts with output drift, which happens when the model’s responses to the same inputs change. Output drift often stems from silent updates to the model or adjustments in its weights. These two types of drift often go hand-in-hand in production settings, and each requires a tailored monitoring approach.
Prompt Drift vs. Output Drift: Key Differences
Understanding the distinction between these two types of drift is critical for effective monitoring. Prompt drift reflects changes in the input distribution, such as users asking more complex questions or using new terminology. On the other hand, output drift is evident when the model’s behavior changes - like providing longer explanations, skipping reasoning steps, or failing to adhere to expected JSON schemas for identical queries.
Traditional statistical methods, like Kolmogorov-Smirnov tests, often fail to detect these shifts because large language model (LLM) drift occurs in high-dimensional embedding spaces rather than in surface-level token patterns. This highlights the need for more advanced detection techniques.
Using Semantic Analysis and Judge LLMs for Detection
An effective way to detect drift involves a two-layer system:
- Layer 1: Convert prompts and responses into embeddings and measure their statistical distance using metrics like Wasserstein distance or cosine similarity. For instance, a cosine similarity score of 1.0 indicates identical meaning, while 0.5 suggests no meaningful relationship.
- Layer 2: When a statistical alert is triggered, use a Judge LLM to identify the cause of the drift. This could be due to shifts in user intent, the introduction of new topics, or an increase in query complexity. To ensure unbiased evaluations, set the Judge LLM’s temperature to zero and use a different model family than the one being assessed. For example, you might use Claude to evaluate outputs from GPT.
Theresa Potratz from InsightFinder AI emphasizes the importance of early detection, stating:
"By the time teams notice clear quality degradation or rising hallucination rates, drift has already been present for weeks or months".
This layered approach helps pinpoint the root cause of drift and allows teams to take corrective action sooner.
Building Baseline Datasets for Comparison
A well-defined baseline provides a clear reference for what "normal" system behavior looks like. To establish this, create a dataset of 50–200 representative prompt-response pairs that cover core, edge, and adversarial cases. Make sure to include details like the exact model version, temperature settings, and retrieval configurations, maintaining full version control.
It’s essential to update this baseline whenever you change model checkpoints, introduce new features that influence user behavior, or notice spikes in unusual prompts. As the Braintrust team advises:
"A well-constructed set of 50 to 200 cases, spanning core use cases, edge cases, and adversarial inputs, provides sufficient signal to detect regressions with reasonable confidence".
Incorporate insights from production traces into your baseline dataset to continuously improve its coverage and ensure it remains relevant over time.
Strategies to Reduce Prompt Drift
To keep AI systems consistent and dependable, it's crucial to prevent prompt drift from occurring again. Think of prompts as you would production code - apply the same level of care, including version control, testing, and thorough documentation.
Version Control and Rollback Capabilities
Prompts should be treated like code artifacts. This means using semantic versioning (SemVer) with a MAJOR.MINOR.PATCH structure:
- MAJOR for significant changes, such as switching from JSON to Markdown output.
- MINOR for backward-compatible updates, like adding new instructions.
- PATCH for small fixes, such as correcting typos.
It's not just about the prompt text - version the entire execution context, including the model version, settings, and retrieval configurations. This ensures you can replicate outputs exactly, even weeks later, for debugging.
Once a prompt version is deployed, make it immutable. This allows for reliable rollbacks when necessary. Teams adopting strong version control practices report faster deployment cycles - up to 70% quicker - and significantly fewer rollback incidents.
Separate prompts from application code by using a centralized registry. This setup enables updates to prompts without needing to redeploy the entire application. Additionally, integrate automated regression gates into your CI/CD pipeline. For instance, block a new prompt version from merging if it scores below a set quality threshold, like 85% accuracy.
After establishing robust version control, move on to validating prompt performance through statistical testing.
A/B Testing for Prompt Stability
A/B testing eliminates guesswork by relying on statistical comparisons of prompt versions in real-world conditions.
Start with a clear hypothesis, such as "Variant B will reduce reasoning errors by 15%". Assign users or sessions randomly to prevent cross-contamination. For equal comparison, use a 50-50 traffic split, but in high-stakes scenarios, consider a 90-10 split (90% control, 10% variant).
Measure two key areas:
- Outcome quality: Metrics like accuracy, relevance, and faithfulness.
- Operational health: Metrics like latency, cost, and token usage.
To isolate the prompt's impact, fix variables like the model snapshot, temperature, and random seeds during testing. Run enough trials to achieve statistical significance, and define decision rules beforehand. For example: "Deploy Variant B if it improves accuracy by 5% without increasing latency by more than 10%". One team saw their success rate rise from 72% to 89% by combining prompt CI/CD with A/B testing.
Documenting Prompt Changes
Proper documentation ensures clarity and accountability, answering key questions: who made the change, when, and why.
Record the full prompt template, model configuration, and the reasoning behind each change. Include evaluation metrics from testing and note any known limitations. Use structured labels like {feature}-{purpose}-{version} (e.g., support-chat-tone-v2) to make the intent of each variant immediately clear. Maintain a centralized CHANGELOG.md file to track all modifications and breaking changes.
This documentation helps pinpoint whether a performance dip stems from a prompt tweak, model update, or input shift. In industries like finance or healthcare, such records are essential for compliance reviews.
Building Systems for Long-Term Consistency
Maintaining prompt consistency over time requires a robust system that keeps track of changes, flags potential issues, and adjusts as your AI evolves. This section dives into strategies for continuous monitoring, centralized prompt management, and reducing reliance on specific providers - each reinforcing the detection and prevention methods mentioned earlier.
Setting Up Continuous Monitoring Workflows
To ensure prompts stay consistent, continuous monitoring is key. A solid monitoring system uses multiple layers. The first layer tracks statistical changes using specific metrics, comparing them to a stable baseline. If deviations exceed acceptable limits, a second layer - often referred to as a "judge LLM" - steps in to assess the nature of the drift. This layer identifies whether the shift stems from new user topics, more complex queries, or changes in user intent.
Start by establishing a baseline during a stable period, which serves as a reference for future comparisons. Go beyond individual responses by implementing slice-level monitoring, which evaluates performance across different segments, such as user intent or content type.
To catch potential issues early, integrate regression testing into your CI/CD pipeline. Every prompt change should undergo automated testing to ensure quality remains high. These tests can block deployment if performance drops below set thresholds, helping maintain a smooth transition through development, staging, and production.
Using Prompt Management Platforms
Platforms like PromptOT streamline the process of managing prompts by centralizing templates, model configurations, version histories, and collaboration tools. These platforms allow you to fetch the active prompt version through an API, letting you tweak AI behavior, adjust tone, or resolve issues without needing to redeploy your entire system.
One standout feature is version immutability: once a prompt is saved, it remains unchanged. Any edits create a new version with a unique identifier, ensuring that production behavior stays reproducible and easy to debug. Role-based access control also adds a layer of security, enabling subject matter experts to test changes in a controlled setting while restricting deployment permissions to authorized users. Without structured prompt management, teams can waste up to 30–40% of their time redoing work or troubleshooting issues.
By combining centralized management with continuous monitoring, prompt versions remain accessible, immutable, and seamlessly integrated into your workflows.
Reducing Provider Dependency with LLM-Agnostic Tools
Reducing reliance on specific providers adds another layer of stability to your AI systems. One way to achieve this is by implementing LLM-agnostic architectures. A unified API layer separates your application logic from individual LLM providers, making it easier to switch models or vendors without rewriting core code.
Tools like PromptOT help by offering a centralized prompt registry with immutable version IDs. This ensures that switching providers doesn’t disrupt operations and keeps outputs reproducible. Studies show that identical tasks phrased with different emotional tones can cause performance variations of up to 40% in production systems. Metrics like PromptSE (Prompt Sensitivity Evaluation) can quantify how well a model maintains consistency across semantically similar prompts. Additionally, research highlights that accuracy can swing by over 45% between the best and worst prompt phrasings for the same task. Building flexibility into your system protects against challenges like model deprecation or sudden API changes.
Conclusion: Managing Prompt Drift for Reliable AI Performance
Prompt drift isn’t just a minor hiccup - it’s a silent disruptor that chips away at AI reliability, drains resources, and diminishes trust. Large language models can fail unpredictably, even without altering a single line of code. As Gunashekar R, a Senior SDET, aptly put it:
"Prompt Drift is the new flakiness of AI systems. Except this time it's not code that's flaky - it's the model." - Gunashekar R
To tackle these challenges, adopting rigorous prompt engineering practices is critical. Just as you would treat production code with care and precision, prompts demand the same level of attention. Systematic testing, especially with well-constructed test cases, uncovers far more issues than manual reviews ever could.
Key Takeaways
- Pin Model Snapshots: Use specific model versions (e.g.,
gpt-4-0613orclaude-3-opus-20240229) to prevent unexpected behavior changes when providers update their models. - Semantic Versioning: Apply versioning practices (MAJOR.MINOR.PATCH) for prompts - MAJOR for breaking changes like output format updates, MINOR for new instructions, and PATCH for minor tweaks .
- Centralized Prompt Management: Store prompts in registries like PromptOT to enable seamless updates, A/B testing, and rollbacks without requiring code redeployment .
- Immutable Prompt Versions: Lock deployed prompts to ensure they remain unchanged. This guarantees that logs and evaluations always reference the exact version used .
- Automated Regression Testing: Integrate regression tests into your CI/CD pipeline to catch and block any prompt changes that degrade performance .
- Golden Dataset: Maintain a core dataset of 50–200 critical use cases and edge cases to rigorously test every prompt iteration.
- Semantic Testing: Use embedding similarity and LLM-as-a-judge scoring instead of relying on exact string matches, as models often rephrase answers while retaining accuracy.
- Environment Tiers: Implement strict promotion gates across Dev, Staging, and Production environments. Prompts should achieve at least 95% accuracy on your golden dataset before being deployed to users .
FAQs
How do I know if it’s prompt drift or a model update?
You can spot prompt drift when you notice small, unexpected changes in the AI's responses, even though the prompts themselves haven’t been altered. On the other hand, a model update typically involves deliberate adjustments to the model’s architecture or training data, which often cause more obvious and widespread changes in output. Keeping a close eye on how the AI's responses evolve can help you tell the difference and maintain steady performance.
What’s the fastest way to set up a golden dataset?
To create a reliable golden dataset, start by clearly defining your scope, goals, and metrics. Next, gather high-quality prompts and scenarios that align with your objectives. Enhance your dataset by incorporating synthetic data where necessary, ensuring it complements your original inputs.
Pay close attention to clear labeling - this is key for accuracy. Regularly update your dataset to include new information, using an iterative approach to refine and improve it over time. Implement version control to track changes and maintain consistency across updates. These practices help ensure your dataset remains accurate and adaptable as needs evolve.
How can I make LLM outputs more consistent in production?
To keep LLM outputs consistent in production, it's essential to follow prompt management practices like versioning, testing, and monitoring.
- Versioning: This allows you to track and reproduce specific prompt states, reducing the risk of unexpected variations caused by minor tweaks.
- Testing: Regular testing, including regression testing, helps identify and fix output drift before it becomes a bigger issue.
- Lifecycle Control: Treat prompts as critical production assets. Implement proper governance and lifecycle management to ensure they remain stable and dependable over time.
By treating prompts with the same care as other production assets, you can maintain reliable and predictable outputs.