
Block order in prompts directly impacts how large language models (LLMs) process and generate responses. The sequence of instructions, context, and examples can significantly influence accuracy, relevance, and consistency. Here’s why it matters:
- Primacy and Recency Effects: LLMs prioritize information at the beginning (primacy) or end (recency) of prompts, while details in the middle often lose importance.
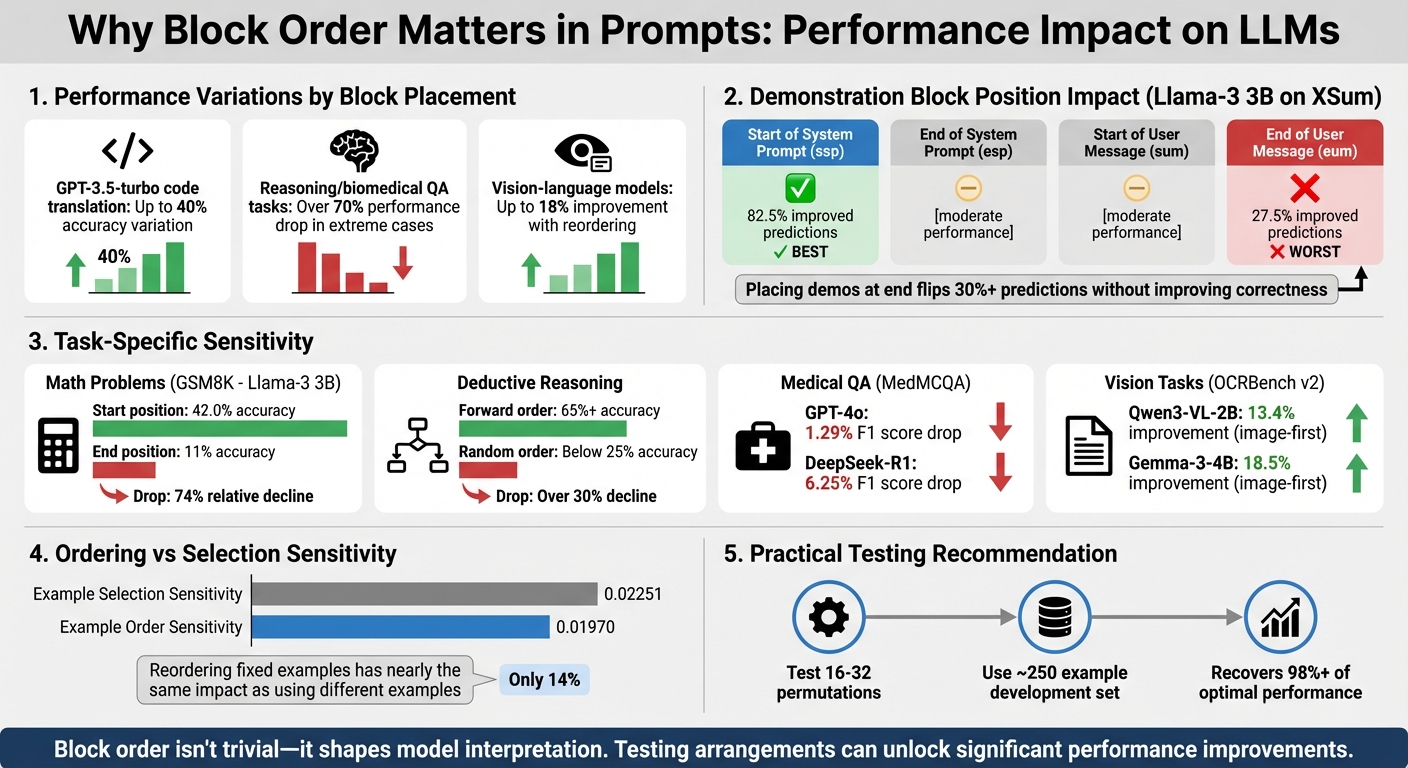
- Performance Variations: Changing block order can lead to drastic shifts in output. For example, GPT-3.5-turbo's accuracy on tasks like code translation can vary by up to 40%.
- Task Sensitivity: Some tasks, like reasoning or biomedical question answering, are highly sensitive to block arrangement, with performance dropping by over 70% in extreme cases.
- Multimodal Models: Vision-language models show improved results (up to 18%) simply by reordering inputs, like placing images before text.
If you’re working with LLMs, testing and optimizing block order is essential for better results. Tools like PromptOT simplify this process, allowing you to experiment with different arrangements efficiently.
Key takeaway: The sequence of information in a prompt is not trivial - it shapes how models interpret and respond to input. Testing multiple arrangements can unlock significant performance improvements.
Impact of Block Order on LLM Performance: Key Statistics and Placement Strategies
Prompt Engineering 101: The Basics of Chunking Your Prompts
sbb-itb-b6d32c9
How Block Order Affects LLM Behavior
Large Language Models (LLMs) process prompts in a sequential manner, building context as they go. This means the placement of information within a prompt directly influences how the model interprets and uses that data. The order of blocks isn’t just a minor detail - it’s a fundamental aspect of how transformer architectures function.
Two key mechanisms explain this behavior. First, primacy bias causes LLMs to place more weight on the information presented early in the prompt. Transformer induction heads, which guide predictions, rely heavily on this initial context. Second, some models exhibit a recency bias, where the most recent information can overshadow earlier inputs. These biases have a measurable impact on performance, as shown in various experiments.
The importance of block order was highlighted in a study by Kwesi Cobbina and Tianyi Zhou from the University of Maryland. In July 2025, they tested the Llama-3 3B model using the XSum benchmark. When a demonstration block was moved from the start of the system prompt to the end of the user message, the rate of improved predictions dropped sharply - from 82.5% to 27.5%. Cobbina explained:
"Placing demos at the start of prompt yields the most stable and accurate outputs with gains of up to +6 points. In contrast, placing demos at the end of the user message flips over 30% of predictions without improving correctness in QA tasks."
Researchers have identified four common positions for demonstration blocks: Start of System Prompt (ssp), End of System Prompt (esp), Start of User Message (sum), and End of User Message (eum). Across various models and tasks, placing demonstrations at the start of the system prompt (ssp) consistently produces the most reliable and accurate results, with accuracy gains reaching up to 18% over zero-shot baselines. On the flip side, placing demonstrations after the user query (eum) often leads to over 30% of predictions being flipped, with no improvement in correctness. These tendencies underscore how LLMs prioritize and process sequential information.
Positional Bias in Demonstration Blocks
In in-context learning, the order of examples can be almost as important as the examples themselves. A 2025 study from UC San Diego found that the performance variance caused by reordering a fixed set of examples was nearly on par with the variance from using entirely different examples. Specifically, the average sensitivity to example selection (0.02251) was only about 14% higher than the sensitivity to example order (0.01970).
This sensitivity isn’t uniform - it varies depending on the model size and task. For instance, when demonstration blocks were moved from the start to the end of the prompt, Llama-3 3B's accuracy on GSM8K math problems plummeted from 42.0% to 11%, a relative drop of 74%. Similarly, placing demonstrations at the end of a user message caused nearly 50% of predictions to flip compared to placing them at the start. Larger models, such as Llama-3 70B, handle these shifts better but still show noticeable performance drops in complex tasks. Beyond the placement of examples, the internal order of reasoning steps further influences outcomes.
Internal Order Effects in Reasoning Prompts
In tasks requiring step-by-step reasoning, aligning the order of premises with the logical flow of the solution yields the best results. This approach, often called "forward order", allows LLMs to perform more effectively. Experiments in deductive reasoning showed that randomizing the order of premises significantly reduced accuracy. For instance, models like Gemini 1.0 Pro and GPT-3.5-turbo saw performance drop from over 65% to below 25% when premises were randomized - a decline of over 30%.
Xinyun Chen from Google DeepMind pointed out:
"LLMs are surprisingly brittle to the ordering of the premises, despite the fact that such ordering does not alter the underlying task."
Interestingly, different models have distinct preferences for reasoning step arrangements. For example, GPT-4-turbo and GPT-3.5-turbo perform better with a backward order (reversing the proof) than with random ordering. However, PaLM 2-L struggles with backward ordering. For chain-of-thought prompting - where reasoning steps are laid out before the final answer - placing these steps at the start of the system prompt tends to create a more stable foundation than appending them after the query.
Block Order Effects Across Different Task Types
The impact of block order can vary significantly depending on the type of task. For example, research highlights that generation tasks, like arithmetic, show a 46% greater sensitivity to the choice of examples than to their order. In contrast, classification tasks demonstrate much less sensitivity, with only a 9% difference when the order changes. Tasks like reading comprehension are particularly affected by shifts in order, while algebra tasks tend to be more stable.
Longer prompts, especially in areas like retrieval-augmented generation and multi-passage question answering (QA), are more prone to performance decreases when the order is shuffled. This has real consequences for systems handling intricate queries. The task-specific nature of this sensitivity is further supported by research in medical and QA-focused applications.
Evidence from Biomedical and QA Studies
Studies in biomedical and QA fields provide clear examples of how task type influences block order sensitivity. Take medical question answering, for instance. A 2025 study used 2,816 validation examples from the MedMCQA dataset to test how shuffling answer choices impacted model performance. For GPT-4o, the F1 score dropped slightly from 0.77 to 0.76 - a 1.29% decline. However, DeepSeek-R1-Distill-Llama-70B experienced a sharper drop, with its F1 score falling from 0.64 to 0.60, a 6.25% decrease. Similarly, in the MSMARCO relevance judgment task, shuffling input passages caused GPT-4o’s F1 score to decline by 6.12%, while GPT-4o mini saw an even larger drop of 12.24%.
Vision-language tasks exhibit even more striking results. In January 2026, Suresh R from GoPenAI tested 89 samples from the OCRBench v2 dataset using Qwen3-VL-2B-instruct. Changing the order by placing the image block before the text instruction (instead of after) boosted the ANLS score from 0.378 to 0.429 - a 13.4% relative gain. For Gemma-3-4B-instruct, the improvement was even more dramatic at 18.5%. In diagram question-answering tasks, this "Image-First" ordering delivered a significant +0.254 ANLS improvement. Suresh R captured the importance of these findings:
"Simply reordering your inputs, putting the image before the text instead of the text before the image, delivers a 13–18% improvement. No model changes. No extra compute."
The encouraging takeaway? You don’t need to test every possible order. Research from UC San Diego shows that evaluating just 16–32 permutations on a small development set (around 250 examples) can recover over 98% of the optimal performance for classification tasks. This makes it feasible to fine-tune block order for specific use cases without exhaustive experimentation. These insights pave the way for practical strategies to manage block order effectively across a variety of tasks.
Practical Strategies for Managing Block Order
If you're looking to fine-tune prompt performance, managing block order can make a significant difference. Think of it as a controlled experiment - keep your content and model settings (like temperature) the same, and focus solely on rearranging the blocks.
One effective approach is the "Instruction Sandwich": begin with your main goal and any non-negotiable constraints, follow with supporting context in the middle, and finish by reiterating key constraints. As Randall Hendricks from Deepchecks puts it, "Context ordering isn't a cosmetic prompt trick. It's part of your model interface, just like an API contract". This structure leverages the psychological principles of primacy and recency, ensuring critical details stick.
When testing, set your model's temperature to 0.0 to eliminate randomness in the results. Use clear labels like "Goal:", "Constraints:", and "Definition:" to keep different sections distinct and avoid blending context. This way, any observed changes in performance can be confidently attributed to block reordering. Keep in mind that different models handle instructions uniquely. For instance, GPT-5 heavily prioritizes rules at the beginning of a prompt, while GPT-5.1 evenly adheres to instructions throughout longer prompts. If your model tends to favor the start of a prompt, place your most important instructions up front.
For those who want to simplify this process, specialized tools can help streamline block arrangement.
Using PromptOT for Block-Based Composition
Manually reordering blocks can become a hassle, especially when dealing with multiple configurations. Tools like PromptOT make this process more manageable. With PromptOT, you can build prompts using distinct, typed blocks - such as role, context, instructions, guardrails, and output format - and rearrange them effortlessly with drag-and-drop functionality.
The platform includes a live preview pane, so you can see how your template variables fit into the block order before running it. This helps catch any potential issues early. It also offers version control, allowing you to experiment with new arrangements and revert to previous setups if needed. For teams, PromptOT's role-based access ensures that subject matter experts can focus on creating content, while developers handle API integration. Additionally, features like "Optimize for LLM" analyze your blocks and suggest structural tweaks. Because PromptOT is compatible with multiple providers, including OpenAI, Anthropic, and Google, you can maintain consistency across different models while testing.
Conclusion and Key Takeaways
Looking at the research and practical strategies, it’s clear that the order of blocks in a prompt plays a major role in how large language models (LLMs) process and respond to input. Studies confirm that order sensitivity is a universal phenomenon, affecting both text-based and multimodal models. Performance can swing dramatically - ranging from top-tier accuracy to random guessing - based solely on how examples are arranged. In fact, the effect of reordering a fixed set of examples is almost as impactful as using entirely different examples, with ordering sensitivity (0.01970) coming within 14% of selection sensitivity (0.02251).
Models also show a positional bias, meaning they give more weight to information at the beginning and end of prompts while often losing track of details in the middle. For multimodal models, the order matters even more - placing an image before text can boost performance by 13–18% without requiring extra computational resources. Similarly, in reasoning tasks, the sequence of JSON keys can make or break performance. For instance, placing "answer" before "reasoning" can completely disrupt Chain-of-Thought reasoning.
"The variance in performance due to different example orderings is comparable to that from using entirely different example sets." - Warren Li, Researcher, UC San Diego
What’s more, the optimal block order depends on the model and task. A setup that works well for one model might not translate to another. Even increasing model size doesn’t reduce this sensitivity - studies show that the Spearman rank correlation between different versions of the same model family can dip as low as -0.09. To maximize performance, it’s recommended to test multiple orderings for your specific use case. Evaluating 16–32 random permutations on a development set can help recover over 98% of the best possible performance.
For teams aiming to put these insights into action, structured tools like PromptOT make the process easier. Features like drag-and-drop block reordering, live previews, and version control allow for seamless experimentation without the hassle of manual edits. Since block order is critical to prompt performance, tools like PromptOT ensure your configurations consistently meet API standards while simplifying the testing process.
FAQs
What block order should I try first for my prompts?
Research indicates that organizing content with examples at the beginning, inputs in the middle, and instructions at the end can be highly effective. This approach helps in a few key ways:
- Minimizes recency bias: By placing examples first, the model avoids overemphasizing the most recent information.
- Prevents verbatim copying: Examples at the start reduce the likelihood of the model directly replicating them.
- Prioritizes instructions: Ending with instructions ensures they stand out during processing, making them easier to follow.
This structure creates a logical flow that improves clarity and processing efficiency.
How can I test block order changes without wasting time?
To test block order effectively, make small, step-by-step adjustments and monitor how the model reacts. By focusing on one change at a time, you can pinpoint its specific impact. Tools like PromptOT, which offer version control and draft states, can simplify the process by enabling easy comparisons and quick reversions. Studies indicate that where information is placed plays a major role in influencing output, making organized testing crucial for gaining valuable insights.
Does block order matter more for reasoning and multimodal prompts?
Block order isn't just a minor detail - it plays a major role in how reasoning and multimodal prompts are processed. The sequence of information directly affects model performance and how attention is distributed across the content.
When key details are positioned strategically, the model is more likely to deliver better results. On the flip side, rearranging blocks can lead to noticeable shifts in performance. This underscores the need for careful and intentional prompt design to ensure the desired outcome.