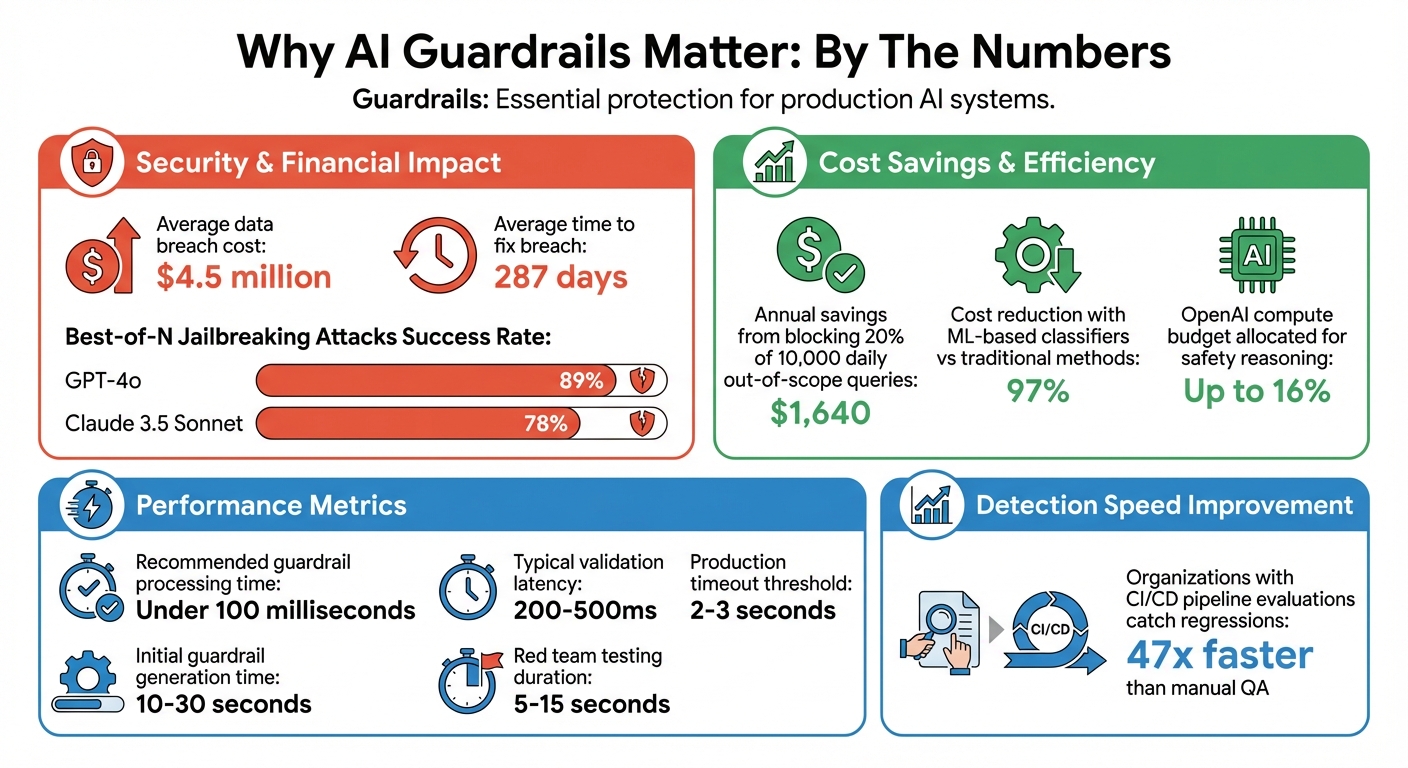
AI systems are powerful but risky. Guardrails make them safer. Without proper safeguards, AI can leak sensitive data, provide wrong advice, or even be manipulated. Recent security breaches, like a Lenovo chatbot hack and a Fortune 500 data leak, highlight the dangers of unregulated AI. These incidents cost companies millions, with an average breach costing $4.5 million and taking 287 days to fix.
What are guardrails? They are safety mechanisms - rules, policies, and code - that filter inputs and outputs to prevent harmful behavior. Examples include blocking malicious prompts, removing sensitive data, and ensuring compliance with regulations like GDPR. Tools like PromptOT help you design these safeguards effectively.
Key Takeaways:
- Input Guardrails: Prevent attacks (e.g., prompt injections) by blocking harmful queries using techniques like regex and semantic analysis.
- Output Guardrails: Ensure responses are safe and accurate by detecting issues like hallucinations, toxic language, and personal information leaks.
- Dynamic Validation: Use runtime data to adapt safeguards to different scenarios.
- Real-Time Monitoring: Catch issues early with automated alerts and validation tools.
Guardrails protect your system, save costs, and build user trust. Start by integrating simple input and output checks, then refine and expand them over time.
AI Guardrails Impact: Security Risks, Costs, and Implementation Benefits
What AI Guardrails Are and Why They Matter
Defining AI Guardrails
AI guardrails act as filters for both inputs and outputs, ensuring that large language model (LLM) applications operate in a way that is ethical, secure, and dependable. On the input side, guardrails work to block things like prompt injections, jailbreaking attempts, or irrelevant queries. On the output side, they help verify responses to prevent issues like hallucinations, toxic language, or leaks of personally identifiable information (PII).
These guardrails are enforced using techniques like rule-based validation, semantic similarity checks, or even a secondary LLM for added oversight. This is especially important because the probabilistic nature of LLMs means their outputs can sometimes be unpredictable or risky.
Why AI Applications Need Guardrails
The inherent unpredictability of LLMs makes guardrails a necessity, especially in production settings. Even identical inputs can yield different outputs, creating risks that need to be managed.
"Deploying Large Language Models in production without guardrails is like launching a website without security - it might work until it doesn't."
– Pratik Bhande, Gen AI Engineer, QED42
Real-world examples highlight the dangers of unregulated LLM behavior. Beyond preventing security vulnerabilities, guardrails also allow faster deployment of new features while keeping specialized bots focused on their intended functions.
There’s a financial upside as well. By blocking out-of-scope queries, guardrails can reduce unnecessary LLM calls, cutting down on operational costs. To maintain a smooth user experience, effective guardrails should process information in under 100 milliseconds. In fact, OpenAI has allocated up to 16% of its compute budget for safety reasoning in certain product launches.
sbb-itb-b6d32c9
Guardrails for LLM Applications | Complete Tutorial for AI Developers WIth Guardrails AI
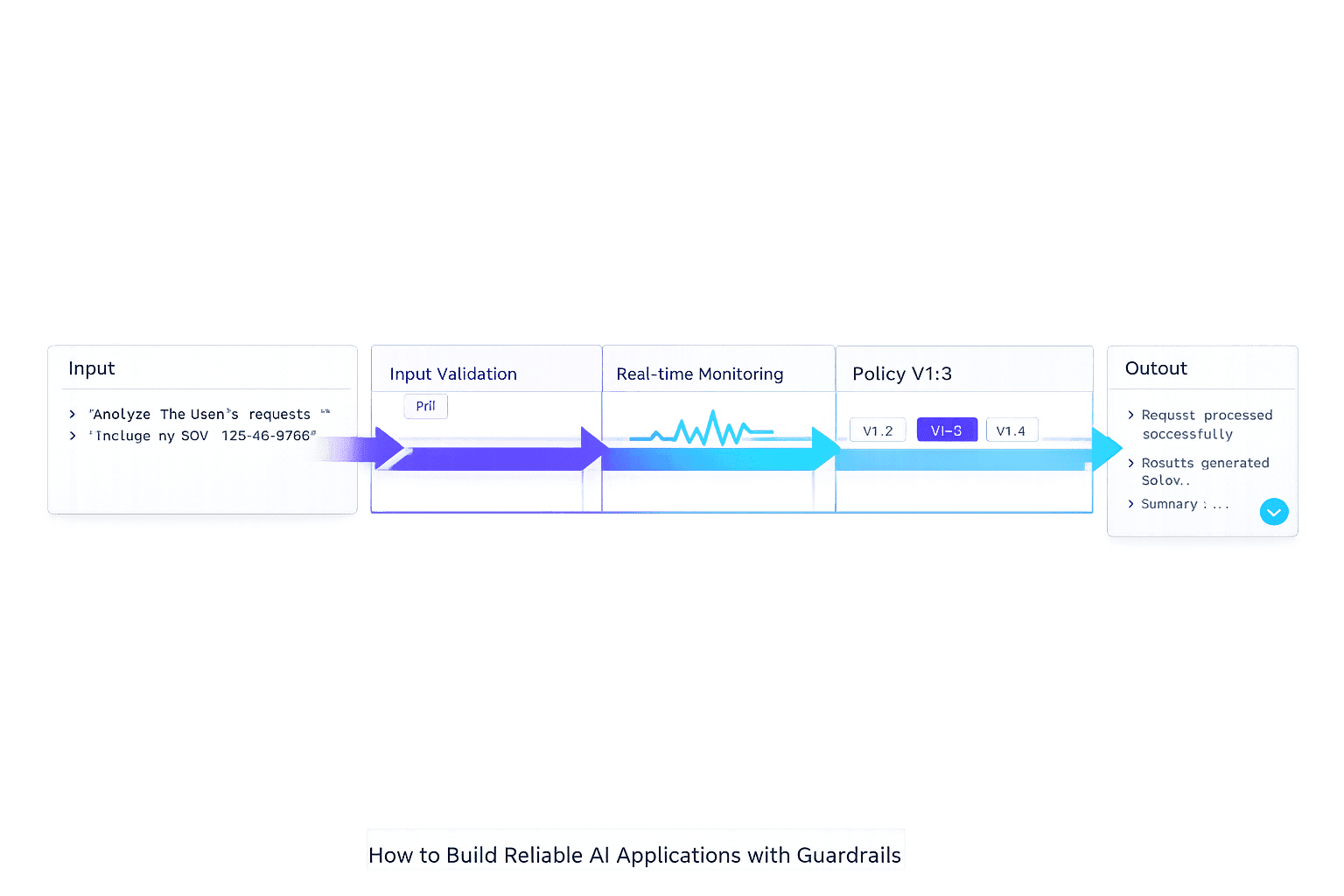
How to Build Guardrails with PromptOT
PromptOT offers a structured way to build layered defenses, known as guardrails, to enhance the reliability of AI systems. These guardrails are implemented as separate prompt components, keeping validation logic distinct from core instructions. By adopting a "defense in depth" strategy, you can apply multiple layers of checks around an LLM call - such as sanitizing input before it's processed and verifying output before it reaches the user. Here's a closer look at how to create these guardrail blocks in PromptOT.
Creating Guardrail Blocks in PromptOT
The process starts by identifying the AI endpoint you want to secure. Once selected, you can add a dedicated guardrail block with clear validation rules. These blocks are designed to align with specific targets, like a customer service bot or a code generator, to reduce the risk of false positives. For input guardrails, you might include measures to block prompt injections or apply topic-based filters. For output guardrails, common checks involve identifying hallucinations or screening for harmful language.
Typed blocks in PromptOT allow for precise validations, even when outputs are unpredictable. You can define expected structures, data types (e.g., integer, string, URL), and quality benchmarks. Using the platform's drag-and-drop interface, you can prioritize when guardrails execute - whether before the main instruction block or after formatting the output. This flexibility also enables running guardrail checks in parallel with the primary LLM call, minimizing delays. If a guardrail flags an issue, it can cancel the main task before it proceeds further.
Using Variable Interpolation for Dynamic Constraints
PromptOT also supports dynamic validation through variable interpolation. Using its {{placeholder}} syntax, you can separate fixed rules from data that changes at runtime. Instead of hardcoding specific values, runtime data - like user input, account details, or retrieved documents - can be injected directly into guardrail logic. For instance, a guardrail block might include: "Check if {{user_input}} contains restricted terms before proceeding".
This method ensures consistency across interactions while adapting to different contexts. A single guardrail template can handle various scenarios by simply swapping out the variable portion, making it easier to scale as your application expands. You can also wrap variables in XML tags, helping the model distinguish between static instructions and dynamic data. When a user submits a prompt, PromptOT resolves all placeholders during runtime and sends the finalized prompt - complete with guardrails - through a single API call.
Validating Inputs and Outputs
Once you've set up guardrail blocks in PromptOT, the next step is to validate both inputs and outputs. Input validation ensures that harmful or malicious prompts don’t reach your model, while output validation safeguards users by ensuring responses are safe, accurate, and compliant. These practices are critical for maintaining the reliability and security discussed throughout this guide.
Input Validation: Stopping Prompt Injection and Errors
Input guardrails act as the first layer of protection against prompt injection attacks. These attacks often involve users trying to bypass system instructions with phrases like "ignore all previous instructions" or "activate developer mode." Studies reveal that Best-of-N jailbreaking attacks have an 89% success rate against GPT-4o and 78% against Claude 3.5 Sonnet when attackers test enough variations. While traditional defenses like rate limiting can increase the cost of such attacks, they don't fully solve the problem.
To address this, use a combination of detection methods in your guardrail blocks. For example:
- Regex pattern matching: Detect specific strings like "system override."
- Fuzzy matching algorithms: Catch variations created through techniques like typoglycemia (e.g., "ignroe" instead of "ignore").
- Input normalization: Standardize inputs by removing extra spaces, repeated characters, and suspicious encoded content like Base64 or Hex.
For more sophisticated threats, semantic analysis can help. By using embedding-based anomaly detection, you can compare inputs against a database of known adversarial patterns, identifying intent-based attacks that simple keyword filters might miss. Colin Jarvis from OpenAI captures the essence of this approach:
"a guardrail is a generic term for detective controls that aim to steer your application".
PromptOT supports asynchronous execution of input guardrails alongside your main LLM call. When a violation is detected, the primary task is canceled, saving both time and API costs. Additional measures like strict character limits and token counts can prevent resource exhaustion and obfuscation attempts. For sensitive tasks - like accessing admin settings or API keys - consider implementing a risk-scoring system to flag high-risk inputs for manual review.
Output Validation: Screening Unsafe Responses
Output guardrails ensure that LLM responses meet safety and quality standards before reaching users. This step prevents issues like hallucinations, PII leaks, toxic content, or responses that conflict with brand guidelines. Common output validation techniques include:
- PII removal: Strip out sensitive information like email addresses or phone numbers using regex.
- Toxicity filtering: Detect and block harmful language.
- Hallucination detection: Identify and address inaccuracies.
- Syntax validation: Ensure structured data (like JSON) is formatted correctly.
While rules-based filters are effective for straightforward issues, more nuanced problems - like subtle toxicity or off-brand sentiment - may require ML-based classifiers or LLM scoring systems like G-Eval. These specialized models can significantly reduce evaluation costs, sometimes by as much as 97% compared to traditional methods.
When designing your validation process, define clear actions for when a response fails validation. Options include:
- Fix: Automatically correct the response.
- Reask: Prompt the LLM to generate a new response.
- Exception: Block the response entirely.
Conor Bronsdon from Galileo highlights the importance of this approach:
"a bad prompt costs less to block than to debug later".
To fine-tune your guardrails, use an evaluation set and confusion matrix to strike a balance between "over-refusals" (which may frustrate users) and "false negatives" (which could harm your business). Regular testing against evasion tactics - like misspellings, coded language, and multilingual bypass attempts - is also essential.
In the next section, we’ll explore how to seamlessly integrate these guardrails into your application for secure and efficient operation.
Integrating Guardrails into Your Application
Once you've established input and output validation, the next step is deploying guardrails effectively. By using an API-driven and version-controlled method, you can seamlessly integrate these guardrails into your application. Thanks to PromptOT's API-first design, you can deploy guardrails without altering your existing codebase or redeploying the entire application.
API Integration for Prompt Delivery
PromptOT simplifies the process by delivering prompts and guardrails through a single REST API call. Each call is tailored to a specific target application or endpoint, using a 1:1 mapping system. Integration starts with environment-specific API keys, ensuring secure staging and production testing. To use it, submit a POST request to https://<instance>/api/v1/guardrails/{targetId}/analyze, including the prompt. The response will indicate whether the input is allowed (allowed boolean) and, if not, provide a reason string.
It's critical to call the guardrail API before sending prompts to your LLM. This step blocks malicious inputs from reaching the model. With validation latencies ranging from 200–500ms and a production timeout of 2–3 seconds, your application can stay secure without compromising performance. If a request is blocked, return a neutral message such as "Request violates usage guidelines" to avoid exposing internal logic.
PromptOT also supports instant rollback via version control. If any issues occur, you can immediately revert to a previous configuration, ensuring minimal disruption.
Managing and Updating Guardrails
Threats evolve, and so must your guardrails. Once integrated, it's essential to manage and update them regularly. PromptOT simplifies this process with draft and published states for updates. You can create a draft version, test it thoroughly in a staging environment, and publish it to production only after confirming its reliability.
Jesse Sumrak from LaunchDarkly highlights the importance of treating guardrails with the same diligence as application code:
"Prompts need to be treated with the same care normally applied to application code. You wouldn't push code straight to production without version control, testing, and proper deployment processes; your prompts deserve the same treatment."
PromptOT's automatic version history keeps track of all changes - what was modified, who made the change, and when. This is invaluable for compliance and debugging. After red team testing, which typically takes 5 to 15 seconds, PromptOT can regenerate guardrails while preserving manual policies and updating automated rules based on new vulnerabilities.
For better collaboration, use structured labeling conventions like {feature}-{purpose}-{version} (e.g., support-chat-tone-v2) to distinguish between guardrail variants. Role-based access control ensures that only authorized team members can review and approve changes using a pull-request style workflow.
Regular updates are key to staying ahead of emerging threats. Regenerate guardrails after every major red team test to address new attack vectors. With initial guardrail generation taking just 10–30 seconds, this process ensures your system adapts quickly to evolving challenges.
Testing, Monitoring, and Handling Failures
Once guardrails are designed and implemented, the next step is ensuring they work effectively in real-world conditions. Testing, monitoring, and managing failures are critical to completing the cycle, taking the process from initial design to deployment and continuous refinement.
Testing and Monitoring Guardrails in Production
Guardrails should only go live after thorough testing confirms their reliability. This involves simulating potential threats like prompt injections (e.g., "ignore previous instructions"), jailbreaking attempts, and evasion tactics such as deliberate misspellings or encoded language. These so-called "red teaming" exercises help uncover weaknesses before they become problems in production. Organizations that integrate evaluations into their CI/CD pipelines are able to catch regressions 47 times faster than those relying solely on manual quality assurance.
Once guardrails are live, it’s important to carefully balance metrics. Use F1-scores and confusion matrices to monitor true and false positives, helping you fine-tune thresholds. For areas like jailbreaking, where risks are high, stricter thresholds are essential. Meanwhile, lower-risk areas - such as tone violations - can afford more leniency.
Keep an eye on both operational metrics (like latency and throughput) and semantic metrics (such as groundedness, toxicity, and faithfulness). Be alert for "drift", which can manifest as shifts in user prompts (input drift) or changes in the model’s behavior (output drift). Catching these issues early prevents broader impacts on users. Automated alerts can be a lifesaver here. For example, set up notifications for unusual activity, such as a 20% spike in violations per hour or a single user submitting over 50 prompts in a minute.
As Swept AI puts it:
"Deploying an LLM without observability is like driving without a dashboard. You know you are moving, but you have no idea how fast, whether the engine is overheating, or how much fuel remains."
Once monitoring shows that guardrails are working effectively, the next step is to prepare for potential failures.
Handling Failures with Fail-Safe Strategies
When a guardrail detects a violation, it’s essential to have a clear, predefined response strategy. The table below outlines common approaches based on the severity of the violation:
| Failure Strategy | Action Taken | Best Use Case |
|---|---|---|
| Fix | Automatically corrects or redacts the content | PII redaction, minor toxicity, or formatting errors |
| Exception | Blocks the response and throws an error | Critical security violations, prompt injections, or severe toxicity |
| Noop | Logs the violation but allows the response | Low-confidence inaccuracies or minor guideline breaches |
| Default/Canned | Returns a predefined safe message | Topical violations or out-of-bounds queries |
For minor issues like PII or formatting errors, a Fix strategy works well, automatically redacting or correcting the content. However, for more severe issues - such as prompt injections or high-level toxicity - an Exception strategy is better, blocking the response entirely and returning a safe fallback message.
In more complex setups, exception-based routing can be useful. This approach allows the application to follow different logic paths depending on which validator flagged the issue. For transient errors like timeouts or rate limits, implementing exponential backoff ensures smoother recovery.
To maintain a strong guardrail system, establish a "Red Team-Eval Flywheel." This means using red teaming to uncover vulnerabilities and immediately turning those findings into test cases for your CI/CD pipeline. As Prompt Guardrails puts it:
"Red team discovers, eval enforces. The flywheel spins."
To minimize delays, run guardrails asynchronously alongside your main LLM calls. Tools like PromptOT’s version history can log all changes and failures, simplifying debugging and ensuring compliance over time.
Advanced Guardrail Patterns
Expanding on the earlier guardrail basics, these advanced patterns are designed to handle more nuanced, industry-specific challenges. Whether it's real-time chatbot interactions or strict compliance scenarios, these techniques ensure precision and reliability where it's needed most.
Real-Time Validation with Streaming Guardrails
Streaming validation processes content from large language models (LLMs) as it’s generated, providing feedback in real time with a dynamic, "typing" effect. Unlike traditional batch validation, where users wait for a full response before checks are applied, streaming evaluates each fragment as it arrives.
For example, in January 2024, Guardrails AI showcased a real-time medical data extraction system using a Pydantic model. By enabling the stream=True parameter and setting on_fail="fix", this system transformed a 30-second batch latency into near-instant updates.
PromptOT supports this functionality by allowing you to set stream=True in your Guard call. This returns a fragment generator instead of a static response. For structured data like JSON, PromptOT validates each fragment against its sub-schema. For unstructured text, it applies validation logic to each chunk as it’s received. Safeer Mohiuddin from Guardrails AI highlights the impact of this approach:
"By coupling streaming responses with Guardrails' advanced verification logic, you can provide users with real-time responses that are both fast and accurate."
Streaming also supports various on_fail behaviors, including fix, refrain, filter, and noop. However, re-asking is not supported, so it’s important to configure your LLM to output only JSON without additional text. This real-time process not only improves user experience but also sets the stage for more specialized validations, as discussed below.
Custom Validators for Domain-Specific Needs
For industries like finance, healthcare, or legal services, standard guardrails often fall short. These sectors demand validations tailored to their unique rules, compliance requirements, and operational constraints. Custom validators address these needs by allowing you to encode specific criteria directly into your system.
To create a custom validator, use the PromptOT CLI command: guardrails hub create-validator my_validator. The validator will return a PassResult when the criteria are met and a FailResult otherwise. For more complex validators meant for broader use, cloning the official Validator-Template repository ensures compatibility with the framework. Additionally, many domain-specific validators rely on runtime metadata - like fact-checking source files or lists of personally identifiable information (PII). You can pass this metadata as a dictionary during the guard.validate or guard() call. If multiple validators are involved, consolidate all runtime arguments into a single metadata dictionary for simplicity.
For high-traffic scenarios, a layered defense strategy can help balance speed and accuracy:
- Layer 1: Quick regex checks (milliseconds)
- Layer 2: Fast classification models (100–500 ms)
- Layer 3: Comprehensive verification for critical decisions (seconds)
Research shows that constrained agents, which operate within strict validation layers, can complete over a million sequential decisions without errors. In contrast, unconstrained agents often suffer from compounding mistakes over time.
Conclusion
Building reliable AI applications means implementing multiple layers of safety. This approach, often referred to as a "defense in depth" strategy, combines strong prompts, high-quality data, output validation, and human oversight. These layers work together to block issues like prompt injections and filter out unsafe responses, ensuring both resilience and efficiency in your systems. By incorporating tools like prompt validation, dynamic constraints, and real-time monitoring, you can create AI systems that are both robust and responsive.
PromptOT plays a key role in this process by allowing you to embed guardrails directly into your prompts. It supports versioning, integrates seamlessly with your instructions, and enables policy updates without requiring redeployment. With features like variable interpolation and API-first delivery, PromptOT helps you iterate quickly while maintaining strict safety protocols. This approach ties together earlier safety strategies, ensuring your systems remain consistently reliable.
The benefits of guardrails extend beyond safety - they also translate into measurable financial and operational efficiencies. For example, blocking just 20% of 10,000 daily out-of-scope queries could save around $1,640 annually in LLM generation costs. Additionally, automated guardrails eliminate what experts call the "confidence tax", which refers to the manual approval processes and late-night monitoring that often delay AI deployment.
"Creating effective guardrails has become one of the most common areas of performance optimization when pushing an LLM from prototype to production."
This insight from Colin Jarvis at OpenAI underscores how critical guardrails are for making AI systems production-ready.
The best way to get started is to begin with simple input and output validation. Monitor blocked queries, refine your rules based on real-world data, and evolve your guardrails over time. This iterative process, outlined throughout this guide, allows you to turn early testing into comprehensive protection. Modern frameworks make this easier by converting vulnerabilities uncovered during testing into actionable protection policies. Even addressing a handful of issues can lead to meaningful improvements, while resolving dozens of vulnerabilities creates a much stronger safety net.
While ensuring AI reliability requires ongoing effort, integrating guardrails into your workflow simplifies deployment and supports high safety standards from the start.
FAQs
What guardrails should I add first?
Start by implementing essential safeguards to tackle critical risks. Focus on input validation, output filtering, and threshold-based controls. For input formats like emails, phone numbers, or URLs, use quick and efficient techniques such as regex or rule-based checks. Add content filters to block harmful outputs and set up protections to prevent the sharing of sensitive data. These basic measures lay a solid groundwork for safety and dependability, with room to incorporate more advanced safeguards as necessary.
How do I reduce false positives?
To cut down on false positives in AI applications, it's crucial to implement strong validation mechanisms. These tools evaluate outputs against clear criteria and reject anything that doesn't meet the required standards. Using structured output generation and input/output safeguards can also help keep results aligned with expectations.
On top of that, real-time monitoring systems and fail-safe prompts play a key role. They can quickly spot and address false positives as they happen, helping to maintain steady and dependable AI performance.
What should happen when a guardrail fails?
When a guardrail doesn't perform as expected, the course of action varies based on its setup. The available responses include:
- Raising an exception: This is triggered with OnFailAction.EXCEPTION to flag the issue immediately.
- Requesting output regeneration: Using OnFailAction.REASK, the system prompts the LLM to generate a new response.
- Taking no action: With OnFailAction.NOOP, the system simply proceeds without intervening.
These responses are designed to ensure reliability and minimize risks by either addressing the error directly or avoiding potentially unsafe outputs.